零壹Lab | 统计学与人文研究的结合如何可能?(下)——清华大学统计学研究中心邓柯博士访谈
发布时间: 2017-03-07 陈静
 公众号:lingyilab
公众号:lingyilab零壹Lab:记录数字媒介之日常,反思科技与人文精神
01Lab: Archiving digital lives, reconceptualizing sci-tech and the humanities
导言:近年来,统计学越来越多地被应用到人文研究领域。从简单的词频统计到复杂的文本挖掘,统计学与人文研究的结合不仅仅带来了人文研究方法的变化,同时也对人文学者形成了影响。他们开始思考如何能在提出问题研究前期阶段就能结合统计学思路与方法去做一些设想。此次零壹Lab访谈对象是清华大学统计学研究中心的邓柯博士,他与人文、社科的学者都有持续合作、研究。此次他从统计学家的视角,谈了他怎么看待统计学与人文研究结合的问题。
“从方法论的角度来讲,算法的推理和人的推理,两个没有多么本质的冲突”
陈:接着上次说,我们之前谈到了有关信息噪音和准确性的问题。我们说到了信息量越大,准确性就可能越高。我的问题就是,作为个体的历史学家的判断事实上经常比运算结果的准确性更高,这个是什么原因?
邓:应该说,从算法角度来说,我们只是说把人,比如说历史学家推理的过程,用了一个程序的或者模型的方式把它数学地、体系地表达出来。通过数学运算和统计学的分析,提取出结果,从逻辑上来讲,与一个历史学家做的事是一样的。但为什么历史学家做得比机器好呢?在我看来,一个学识很渊博的历史学家事实上有更多的信息在他的脑子里面。在目前的技术条件下,如果我们机器不知道历史学家脑子里的那些信息,只依赖于已得到的部分数据本身,那我们可能只能做到这一点。但是我觉得这个问题从方法论的角度来讲,算法的推理和人的推理,两个没有多么本质的冲突。算法的一个作用就是,把人的一种思维方式用一种数学的结构呈现出来,然后利用计算机的计算速度和大容量来运算。比如说,一个专家同时考虑一百万个人物和一亿条关系,仅靠大脑是没有办法处理这个规模的数据的。但是从计算机角度来说是没有问题的,它可以综合处理这么大量的数据。而且在算法在处理这些数据的过程中,它所用的方法论,从本质上而言和一个人文学者推理的方法论并没有区别。它只是把这个方法论在工程上放大,然后可以处理更大规模的信息,做得更快,然后由于它的快速性和它对资料的全局性,计算机有可能做得更精准。所以我觉得第二个层面意义上来说,大概就是我们努力的一个方向。
陈:实际上现在这一步还没做到?
邓:我们现在应该说已经基本上快做到了。就包括我们现在和包弼德教授团队在做的那个方法,理论部分其实都出来了,我们现在就是在做程序调试。在更大范围上我不敢说,但在处理CBDB的矛盾冲突和噪声的自动剔除上,我觉得我们很大程度上是可以解决的,做好的话实际上是可以帮助CBDB快速地迭代。就是说,以前的数据库可能有很多错误,除非专家指出来,我们是可能很难自觉地去提取并完善的。现在有了这样一个机制以后,就可以很快地让计算机去发现问题。我们现在的期望就是,当我们在处理人物关系的时候,可以做一个列表出来,进行自动推荐、推送,告知你这里的人物关系有冲突,那里关系有冲突,在什么地方有冲突。这样的话,我们就能有个冲突列表,就可以让人很快地干预,去看看到底哪儿有问题。这样,系统就可以很快出现一个迭代。
还有一种办法就是说,把有问题的部分先冻住,就是说程序会首先意识到现有的数据库里的一部分信息肯定是有问题的,我们就可以在数据库里把这部分先剥离出来。这个的结果就是,之前我们在不知道的情况下,把有问题、没问题的信息都发布出去了,很容易引起批评,但如果我们有了这么一个质量控制的机制,先做一个内部的测评,把有问题的部分先摘出来,在后台先进行一些处理。这样的话,数据库的精度从质量上来讲会得到提高。就像工厂一样,我们不能保证我们生产线上生产的每一样产品都是合格的,一定会有残次品,但如果有一个机制,把残次品留在工厂里边,随后再去处理,那么实际效果也是好的。我觉得在CBDB这个项目上,用这种思路去解决问题也是一种合理的解决方法。
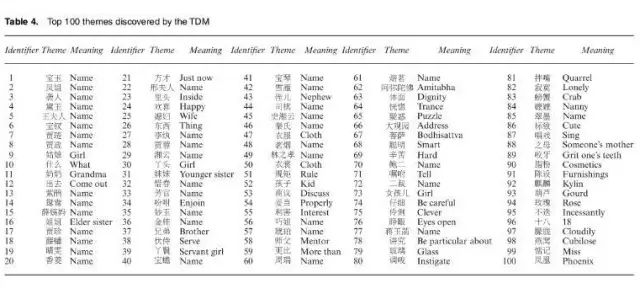
(《红楼梦》的前100主题)
“ 我们可以想办法建立一个犯错概率的认知,对错误有个预判,后面做的效率更高”
陈:如果把纠错这个问题做好,影响还是重要的。特别是应用在开放式的系统里面,如果是采用众包的方式来输入信息,这种预测和识别这就很有意义了。因为多人提供的信息会错误很多,准确率连百分之七八十可能都达不到,就需要这样一种自动识别错误的机制,对可能错误的信息过滤一遍,然后判断出一种准确性。
邓:从我角度来讲,应该是可以做的,而且据我了解,别的领域已经做了很多有意义的尝试。说到众包问题,因为参与的人都可能犯错,所以我们可以想办法建立一个犯错概率的认知,对错误有个预判,后面做的效率更高。
陈:怎么对这个概率有认知?
邓:可以让参与众包的人在回答问题的时候做一些测试,比如说放进去百分之三或百分之五的问题是我们已经知道答案的,然后就让他去做。当然,我们希望他回答的问题和我们已知答案的这些问题,在难度各方面几乎是一样的,是有代表性的。这样的话,可以根据他回答的过程,评估出一个数据的质量出来。 如果我们在给他们题目的时候做点设计,有一些题目是多个人交叉去答的,就可以对结果做一个递增回归。比如说一个人可能会犯错的概率是百分之十,一个人答一百道题可能十道他犯了错,另外一个人可能好一点,答一百道题有五道题犯错。那如果你有三个人或者四个人同时在答一道题的时候,你当然很容易把所有答案都整合出来,就可以说出哪个答案是对的,哪个答案是错的。
陈:但是这个问题还是取决于你要对他有一个训练的过程或者一个测试的过程。但是如果系统是开放的,不存在那个让他问答测试质量的阶段,直接就对照片、文本进行标记,这个结果就很难测了。
邓:如果说这个信息完全没有的话,就会变得比较困难了。但如果我们在系统里设置让参与者必须去参加一些环节测试,对他的基本参数有一定的估计,那么这个事儿就有可能做到。
(新浪微博里的主题发现)
“ 很多人在做这个领域的研究说明这个问题很重要,而且说明这个问题还没有得到一个很好的解决”
陈:那我们接着之前的,到下一个相关性的问题。比如说做中文文本挖掘,你现在跟CBDB合作,莱顿大学的MARKUS也在做,然后台湾大学也有老师们在做。 你怎么看待不同团队在方法上的差异性和重复性?大家有没有必要同时去对一个问题用不同的方法去做,或者说,在这样一个过程当中是不是存在所谓的资源浪费?
邓:我不这么认为。我觉得有很多这样的情况,从学术的角度来说,是一个非常好的现象。我是说同一个问题,有很多不同的研究团队在做研究。首先,这其实说明几个问题。第一,大家都觉得这个问题很重要,所以愿意去投入时间和精力去解决它。第二,也说明大家都感觉到这个问题还没有很好地得到解决,所以才都去做。举例来说,就像现在学术界,从计算机的角度大家可能很少去做数据库了。因为数据库这个东西从学术研究的角度来讲已经很成熟了,所以现在主要是产业在做这件事情,不太需要大家去做研究了。换句话讲,很多人在做这个领域的研究说明这个问题很重要,而且说明这个问题还没有得到一个很好的解决。所以,我也不认为有很多团队去做是一种浪费。而且,从学术来说,我觉得这是一个非常好的现象:正是由于很多人从不同的角度去思考,提出很多有创意的思路和方法来解决这个问题,最后慢慢地,这个问题才能得到更好地解决。
当然,我个人并不希望一直是这样的一种过程——五年时间,十年时间,二十年之后还是这样一个过程就不好了,说明过去二十年这方面研究没有一个本质性的进展,大家还是在那儿不知道怎么做,还是在不停地提方法。我更希望通过大家的努力,一年、两年、三年甚至五年,到了一定时候,大家会觉得说这个问题已经有一个非常好的方法了,基本上解决了,那大家就会自然而然地用这个方法去解决问题,把注意力和精力转移到别的地方。就我个人体验而言,在这个过程中,不同领域的专家从不同角度去探索,都提了一些非常好、非常有创意的一些思想,我在交流当中也学到了很多很多东西。
陈:那你们之间互相聊吗?
邓:交流啊,包括有很多学术会议。我们学者间的研究合作也都会有交流。合作的学者有的是统计学家,有的是计算机科学家,大家会一起开会、讨论、交流等等,我觉得观念还是比较开放的 。我们也组织过好多次学术交流,像前几年我们和包弼德教授一起在哈佛组织过一个关于中文文本分析的学术会议,2016年一月,清华、北大和CBDB团队也一起组织了学术会议。我们也参加过很多国内的学术会议。特别是我们也和计算机领域的专家常在一起讨论,比如我们清华计算机系的孙茂松教授,在这个领域做得非常优秀的,我们和他们的研究团队都有这样的交流,我觉得这个本身是对中文文本挖掘是数字人文的学术发展非常有用的。

(部分结果截图:民国《汉口中西报》和《越华报》广告文本中的全文切词效果)
“ 我认为,统计学,比如在无指导中文文本分析的这个问题上,能提出解决问题的一个新思路”
陈:我们知道统计学家和计算机科学家在方法和思路上还有差别,那你们在交流的过程中,有没有发现在处理中文文本方面有什么不一样的地方?
邓:我觉得计算机学家在处理问题的时候思路与统计学家还是有点差别的。比如说他们的一个习惯思维方式就是,先把所有的背景给剥离掉,只有文本。文本无非就是说主语、谓语、宾语,弄清楚以后再做分析。我认为,统计学,比如在无指导中文文本分析的这个问题上,能提出解决问题的一个新思路。当然我也不能保证这个最后一定能做的非常好,但我觉得这会是和以前的思路不太一样。为什么呢?因为我会意识到,这个文本的结构和它里面的信息实际上是非常复杂的。因为它文本会有很多微观、局部层次上的信息。从一个词来说,你从语法来分析,它是主语还是谓语,是动词还是名词,是形容词还是副词,大家从语法上(分析)就非常有意义。但是对于我们很多人文学应用而言,从语法的层面上给它出来一些标注和分类,实际上可能没什么用。
换而言之,我个人的理解是,对于今天人文学研究来讲,这种精细程度还是不够的。同样是名词,在这个项目上,我可能很关注你的人名、地名、官名,这些词具有的意义不一样的。但在别的研究里,我们可能特别关注一些特定的地名、河流的名称、水利工程名称。传统的、以语法结构为导向的分类体系或标注体系,实际上并不是为了具体的研究兴趣服务的。它的标注体系是很粗的,它的服务对象不完全是为了后面的研究,很大程度上是从一个语法的意义上做一些标注。在我看来,这个就造成了以前的研究范式与当前的人文研究需求之间的一个脱节。
那么这个脱节会造成一个什么问题呢?对于不同的数字人文研究项目,每个研究的关注点都是不一样的,会引发学者的兴趣点也不一样。面对多样性的需求,我觉得是不大有可能有一个通用的方法,一下子就能把所有的信息都捕捉到,把所有的问题都解决掉。现在已有的通用方法只是在语法意义上去做,但又与具体研究需求之间有一个很明显的落差。所以我觉得从技术的发展和路线来讲,有一个思路上的差别。在我们做统计研究的人看来,数据不应该被看成是死的数据。统计学家的“惯例”就是,一定要将数据和研究聚焦的问题结合,针对具体问题用不同的方法和模型来处理,对特别关注的特征进行建模,别的东西可能就忽略掉了。这样的话,数据模型不至于太复杂,可运算、可操作、可分析。但同时,得到的结果也可以很有针对性地回答学者提出的问题。脱离开具体背景和问题做一个特别大而全的方法,在我看来实际是做不到的,而且也不能真正帮得上忙。
(部分结果截图:“韦廉士红色大补丸”广告全文中的词组)
邓柯
· 北京大学统计学博士、哈佛大学统计系博士后、副研究员
· 清华大学统计学研究中心副主任
· 研究兴趣:统计建模、统计计算、生物信息、文本分析、计算机网络透视
· 论文发表于PNAS, Journal of Royal Statistics Association (Series B), Journal of American Statistics Association, Annuals of Applied Statistics 和 Statistics in Medicine
· 2014年入选“青年千人计划”
主编:陈静 责编:徐力恒 顾佳蕙 美编:傅春妍


关注零壹Lab,获取更多数字人文信息!