零壹Lab | 自我重复与东亚文学现代性,1900—1930(上)
发布时间: 2018-07-27 霍伊特•朗、戴安德
 公众号:lingyilab
公众号:lingyilab零壹Lab:记录数字媒介之日常,反思科技与人文精神
01Lab: Archiving digital lives, reconceptualizing sci-tech and the humanities
作者简介:霍伊特•朗(Hoyt Long),美国芝加哥大学东亚语言与文化系副教授,研究方向为日本近代文学、媒体历史、文学社会学与数字人文。
戴安德(Anatoly Detwyler),美国哥伦比亚大学东亚语言与文化系教师,研究方向为中国现代文学和数字人文。
朱远骋,美国宾夕法尼亚大学沃顿商学院研究员,研究方向为统计学。
译者简介:汪蘅,毕业于北京大学英语系,自由译者。其中日本作家近松秋江的一段话、武者小路实笃的两段话由深圳大学日语系曾嵘老师从日文原文译成中文。
转载已获得授权,原文刊发于《山东社会科学》
2018年第7期,在此感谢
◆ ◆ ◆ ◆ ◆
东亚文学现代性的历史往往作为叙事自我(narrative self)的史学(historiographies)开始。对某些学者而言,20世纪初出现的明确自我指涉(self-referential)的小说模式是界定此种现代性的重要部分。[2]日本有“私小说”(I-novel),在中国是浪漫主义小说(Romantic fiction)。二者被认为是基础类型,采用狭窄的自传体焦点、冗长的心理叙述和新的白话写作风格,将自己同之前的小说区分开。同时,其他人则力求以更精确的风格或形式术语界定这些类型。爱德华•富勒在谈及私小说时曾说:“关于(它)的写作不是不像追逐沙漠绿洲……评论家已就此争论远超半世纪而未能提出可行定义,这种形式该如何分析?”[3]中国浪漫主义小说的情况与此相仿,自夏志清和李欧梵的研究以来,人们照例以其社会环境而非一组一致的类型性质来定义它。[4]
定义上的模糊对文学学者如何理解类型必不可少:任何文本的身份识别总是多元决定(overdetermined) 的。同样重要的还有这样一种观念,认为几组文本能够通过将自己与其他文本区分开而保持一致。本文中我们使用计算方法,认为对于现在列在“私小说”和浪漫主义文学标志下的叙事实践,词汇重复的加强趋势是个显著的一致点。我们所说的趋势比所有自我指涉的作品都有的基本特征弱,但比仅有少量作品才有的次要特征强。这一趋势在两种文化语境中都存在,这促使我们思考重复在文学风格中的作用,以及其作为一种文学风格的作用。一方面,我们认为重复指明了与私小说和浪漫主义文学都相关的具体的形式转化:写作的白话化和对西式语法结构的采纳。另一方面,我们认为重复也与内容层面上的变化有关,尤其和重视叙述心理现实主义和精神失常有关。在这方面,作为风格的重复是一种表面现象,辨识了在自我的智识成形(figuration) 和确定的语言战略之间发生的一组更深刻复杂的相互作用。我们认为,透过计算察看这个表面,开启了新的比较框架,可分析东亚文学现代性的空间内这些相互作用的效用。
我们的论证分为三部分。第一部分,我们建立理论基础,将重复性与学者早先归于日本私小说和中国浪漫主义小说的一组定性特征(qualitative traits)相联系。在收集了一组可测量的、抓住了语言中不同重复种类的语言特点后,我们测试了这些特点和同时期小说作品相比在多大程度上是这些类型的典型特征。第二部分,过去在审美、社会语言学和心理学方面对重复的学术研究认为,重复对意义构建十分重要,我们借鉴这方面的研究,讨论了我们的实验发现。通过评估文学评论家和语言学家如何尝试为语言中的重复建立模型、对比定性和定量建立模型的不同优势,我们赋予定量模型历史意义,并表明它已经与之前从语言表面解读反常心理过程症状的努力紧密相关。第三部分,我们转向几个在分析中确认的重复最多的段落,思考如何从文本表面解读作为风格的重复。我们确信有多种解读方式:作为风格趋势,连接跨越文化和语言边界的文学关系;作为出于不同审美目的而由作者激活的趋势;最后,作为建立在语义意义或意识形态基础上的比较框架的补充。
>>>>一、作为趋势的重复(Repetition as Tendency)
在日本,文学的自我塑造(self-fashioning)这一现代事业是在19、20世纪之交后严肃开启并于1910年代繁荣起来的。这种写作追溯性地集合在“私小说”(shishosetsu)的标签下,其中许多将自然主义的具象逻辑 (representational logic)转化为痴迷于记录自我的内心思想和日常经验,无论其有多令人震惊或庸常。在一位日本评论家1909年所称的这个“自白的年代”,中国“五四”一代作家中有许多当时以学生身份居住在日本。[5]其中一些回国后,于1921年组成了创造社,如今这个文学群体与考察并探索个人主体性的浪漫主义兴趣紧密相连。私小说和浪漫主义作家一起产生了形形色色的自我指涉写作,对日本和中国现代小说史都极 为重要。
但是正典产生了一致性问题,这些归类也一样。数十年来对这些作家的学术研究表明,没有什么单一因素能界定其小说。评论家分离出贯穿其中的诸多意识形态趋势,质疑其时间内聚性(temporal cohesion),并将其叙事小说的地位问题化,以此对文本一致性提出争议。[6]私小说和浪漫主义小说是否是有意义的类型标签依然模糊,这甚至导致了极端的相对主义主张,全然否认存在一致的形式或类型;声称这些标签只是不着边际的话语和意识形态范式,可通过它阅读任何文本。[7]有的学者虽然没有否认此类文学中存在变化,却从相反的假设出发,将私小说和浪漫主义小说看作有明确形式或实证模式的类型。他们关注叙事结构、修辞风格或社会和媒介语境,试图分离出一套能维系这些文本的特征。[8]
我们在本文中的目标并非要统辖这一持续的类型辩论,这样做会有失我们作为评论家的身份。没有解决这一争论的单一途径,因为对这些类型标签本体论现实(ontological reality )的辩护或反对都建立在对比较单位的不同假设上。是作者、理想的读者,还是文本的某些方面?在这里,我们明确将注意力集中于共同的语言模式。它们提供了比较的范围,包含数以千计的文本和多种语言语境。它们也提供了粒度(granularity ) 层面,可通过这个层面观察汇聚一起的风格趋势,以实例说明作为文学建构的现代自我。或者借用弗兰克• 莫雷蒂对布尔乔亚风格的分析,作为由“无意识的语法模式和语义联合、而非清晰明确的观念”组成的“精神 状态”。[9]我们需要回答的第一个问题是:在“私小说”和“浪漫主义”标签下的小说中是否存在任何这种精神状态。
最初提到,有几个高阶现象(higher order phenomena)表现了这组小说的特点。学者们早已注意到它的兴起分别与日本的“言文一致”(genbun - itchi )和中国的白话文运动影响下现代书面白话文的强化密切相连。还有人指出与白话化同时发生的对舶来的叙事技巧和欧化语法的广泛实验,但与前者迥然不同。[10]一方面,这些舶来品包括自由间接引语、漫长的内心独白、拒绝情节设置等。[11]另一方面,也包括使用人称代词、物做主语、西式句法和对主/宾关系夸张的说明等。确实,日语和汉语作为非屈折语,传统上对于句子中是否具有语法上的主语有很大灵活性,很多人关注在创造新的自我叙述结构的同时,这两种语言是否会被施加影 响并改变外形。在日语的情况中,有人认为这种灵活性使得叙事权能(narratorial authority )和人物视角间发生滑移(slippage),模糊了私小说作为现实主义小说的身份。[12]
虽然这些复杂的文学语言发展为理解自我指涉小说的独特性提供了重要基础,但它们作为特征并不能 很好地作出衡量,也不一定能将此类小说同其他也采用相仿的白话风格或西式语法结构的当代类型分隔开。因此我们的目标是找到一组定量测量方法,能让我们比较数百个文本,同时有可能在自我指涉小说中挑出能指示这些高阶现象的语言趋势。这些现象曾经捕获了其对文学语言影响的某些方面,现在实际意味着我们要为它们创造有效的指标(proxy)。从情节和叙事的角度,我们推断,相比情节驱动的作品及其更动态的叙事焦点,这些文本更强烈的心理学焦点可能更适于语义场的收缩和更小的词汇多样性。换句话说,私小说和浪漫主义小说是否倾向于将词汇焦点集中在更小的词汇表上?另外,从风格的角度我们推测,向白话文写作转移的一个结果可能是语言中重复和冗余增加。采用西式语法特征,尤其是每句话中指明主语和宾语这一倾向可能只会进一步加剧这种趋势。
虽然有些推断只是合理的直觉,但是在与书面词语相关的情况下如何理解口述性这方面,我们对白话文写作的假设有很长历史。如果我们将冗余理解为某些语言单位(即字母、音素、语素)的重复,要么因为它们在语境上彼此依赖,要么因为它们强化了信息的可信性,那么所有的自然语言本质上都是冗余的。[13]它们建立于其上的规则和惯例允许我们预测——例如——跟在另一个单词或一系列单词后的那个词,并因此能够省去上下文暗示的词。许多人认为这种内置的语言冗余一般在口语和口头文化中更为极端。瓦尔特•翁 (Walter Ong)在米尔曼•帕里(Milman Parry)关于当代南斯拉夫口传史诗的研究基础上认为,固定套话表达和重复有助于口头文化里的记忆,在口头讲述的话语里,“大脑必须前进得更慢,紧跟注意焦点,其中大部分是它已经处理过的内容。冗余,即重复刚说过的话,保证说话人和听者在轨道上。”[14]研究对话的语言学家指出“重复不仅位于特定话语如何被创造(在说话者之间)的核心,而且位于话语本身如何被创造的核心”;这个观念也被文学学者采用,以确定西式文本中口语风格的语言标记(markers)。[15]我们想知道,在何种程度上,口述性的这种重复特质在日语和汉语文学新的白话风格中显明自己?
幸运的是,语言学家对重复的持续兴趣产生了大量定量测量,以捕捉冗余和词汇多样性的各个方面。其中许多测量方法,尤其单词为主要分析单位的测量,其共同来源是1930年代到1950年代间在美国和欧洲研究的心理语言学领域,这段时间的特点是人们对用于教学或临床评估的词汇多样性测量方法的开发的广泛兴趣。研究人员想知道,考虑到特定的写作或言语样本,是相同单词以更高频率重复得更多,还是许多不同单词以较低频率使用? 1935年,乔治•齐普夫阐述了以他名字命名的法则,声明在给定的自然语言样本中,词频排名的分布遵循幂定律,因此任何单词的频率与其在频率表上的排名成反比(也就是说,最常见的词出现的次数是排名第二的常见词的2倍,以此类推)。1938年,约翰• B •卡罗尔开发了多样性测量方法,其基础是观察到单词多样性随着文本规模的增长必然接近极限。他的测量关注的是常见词在一篇文章中倾向于重复的频率,他断言这样的测量方式有助于评估人的言语行为与语言规范间的相对遵循度。[16]第二年,温德尔•约翰逊引入了类符—型符比(TTR):文本中独特的单词的数量除以总单词量。他猜想这个比例可以作为“窘迫或迷失程度的测量方式”起作用,而且可以帮助定量“一根筋”或者“偏执狂”现象。[17]1940年代见证了更多建立在这些基础性测量方法上的尝试,以便评估给定文本片段中的词汇有多重复、统一或集中。简单来说,其中有些测量方法拥有对文本长度变化较不敏感的优势,能够减弱或忽略罕见词的影响。
引人注目的是,它们还和一种在1950年代变得非常有影响的测量方式共享数理关系:熵,它代表了从另 一角度解决重复问题的测量方法。有些心理语言学家追随克劳德•香农和华伦•韦弗在贝尔实验室的研究,开始用更基于概率的(probabilistic )方法处理重复,不仅分析使用的单词的多样性,还分析单词先后顺序的可预测性,也称为“转移概率”(transitional probabilities)。他们通过冗余和信息的双透镜重新聚焦了有关重复的观念。在一个信息论文本中,一条消息的冗余量(它的熵)反应了其中的“信息”量。此处信息指基于所有可用组成单位基础上的消息的可能性,也是在统辖所有组成单位排列方式的现存规则或模式条件下、所有的单位组合方式的可能性。简单说,信息代表了初始限制条件下,一条消息能以多少种不同方式构建。那么,信息极其丰富的语言也许就是其中任何给定单词都有均等机会出现在彼此旁边的语言。这种人造语言中,每条消息都携带新信息,因为每条消息都和它之前那条同样随机、不可预测。这些消息也将完全无法理解,这也是为什么所有自然语言都有某些内置的冗余。
尽管熵证明对许多心理语言学家而言是理论上富有成效的概念,但是要用任何整体方法测量它也确实非常棘手。它不仅随着测量中的文本长度变化,还随着研究中的序列长度和分析单位变化。序列变长时,用于预测本序列中下一项目随机性的潜在组合的数量也会变大。因此,熵会随文本或语料库被测部分的多少而发生偏向,也会随着单位数量及其潜在组合数量的增加而越来越难以处理。从实践中看,这意味着初期将熵用于文本受限于较小的分析单位(即字母、音节),因为人们可能期待在给定的部分文本中看到更完整的潜在组合的区间。[18]这也意味着焦点保持在个体的词或词对上,就像古斯塔夫•赫尔丹用熵推断作家在写作中如何操纵表达法的可变性以避免不恰当的重复。[19]受限于个体单词层面时,熵仅仅捕捉样本全部单词在该样本中可用的不同单词中的分布。这种情况下,熵最低的段落就是每个单词都独特、不同的段落;熵最高的段落中每个词都相同,因此高度冗余。[20]
测量词汇多样性和熵的不同方法虽有局限,但也确实提供了量化文本重复量的基线。用这个基线,我们首先确定了与同时期写作的其他小说相比,私小说或浪漫主义小说是否显示了夸张的重复倾向。白话风格、西式语法结构和心理聚焦相结合,是否转化为更狭窄的单词范围并重复得更多?为了回答这个问题,我们首 先为每种语言构建了语料库。在日本文学方面,我们收集了学者专门指定或解读为私小说类型的约65种文本。我们还收人了自我指涉或心理作品,其作者与此种类型有关或只暂时以此种写作模式做实验。作品大部分出版于1910年代和1920年代,约30位作者。之后我们收集了规模相仿的通俗语料库,我们期待它们 在内容和叙事焦点层面明显偏离,但在文学语言层面并不如此。它主要是1920年代和1930年代由现代白 话风格写就的高度情节化的历史小说和侦探小说。[21]
因为缺乏对等的通俗类型小说语料库,我们对中国文学采取了略为不同的方法。首先,我们确定了与创造社密切相关的主要“五四”作家的100多个浪漫主义文本,包括郁达夫、郭沫若和张资平等的1920年代作品。不过我们的控制组是一组100本同时代通俗文学作品,例如历史演义小说和“鸳鸯蝴蝶派”故事。[22]虽然选择这些作品是因其高度情节化的特质以及缺乏心理聚焦,这和日本的情况一样,但其中大多数也以旧白话风格写作,这同浪漫派作家发展出的白话文模式显著不同。所以这种情况下是从内容和语言风格方面作比较。尽管有此差异,我们在两种情况下的目标都是要明确,对重复和冗余的各种测量方法是否足以界定私小说和浪漫主义小说有类型上与众不同的倾向,超越了纸页上字词的意义。
因此下一步是应用这些测量方法。因为像TTR和熵这样的测量方法往往与所测段落的长度高度相关,所以对它们的应用要使结果独立于文本长度。尤其对这两种方法,这意味着将文本分为1000字片段;测量这批片段的TTR和熵,包括停用词(stopwords);再计算文本所有片段的平均值、标准差和累计和(方程1)。

标准差告诉我们所有语块(chunks)TT和熵的波动,累计和告诉我们数值趋于比均值高或低多少。我们意识到我们的熵值测量法与个体词的边际分布相关,考虑到其序列本质,也在词的联合分布基础上计算了熵。借自伊奥阿尼斯•孔托伊阿尼斯的这个方法采取非参数角度,捕捉词序或字序间的远程关系(long- range dependencies)。[23]这里我们选择关注个体音标和汉字的序列,这样一来,较低傭值就说明相同字序列的重复更多。虽然用于找到配对序列的窗口的规模依然取决于我们最短文本的长度,使得到的熵估计(entropy estimates)有所偏差,但估计值本身与文本长度无关。
我们担心仅有TTR和熵给重复提供的窗口太窄,另外应用了两个数理上与熵有关但原本作为词汇多样性指标而创造的特征。第一个是乔治•尤尔的“特征K”,于1944年开发出来测量文本中的词汇重复性或一致性。它依靠词序和频率做计算,将所有词频之和与特定频率单词的数量相关联,尤尔的设计使之独立于样本规模。[24]它还预设特定文本样本中词的发生遵循泊松分布(Poisson distribution),将词作为任何间隔(即样本长度)中以已知平均比率发生的固定事件(fixed event)处理。赫尔丹后来校正了这一推测,开发了调整后的K,在60年代被广泛用作词汇集中度的风格测量方法,包括尝试分析精神分裂语言。[25]我们纳入的另一个特征是词汇集中度指标,也是在1944年,由法国语言学家皮埃尔•吉罗开发的众所周知的“吉罗的C”,表示文本累积词频的比例由文本中最常见的50个“实义”词(content words)所占据。高指标值表示“作者将注意力集中在相对狭窄的、具有完全意义的单词范围内”,反过来也证明了“主题的紧凑、主旨的集中,(和)某些情况下的现成句子”[26]。这个测量方法比尤尔的K对文本长度敏感,因此解释力较弱,但它的解释更直观。二者都有无需将文本分为小块的益处。重要的是,二者都和熵类似,依赖相对词频之和。[27]
我们逐一检查了这些测量方法,发现几乎所有方法都擅长将私小说和浪漫主义小说与同时期通俗作品区分开。日语语料库平均TTR和熵的分布表明,私小说一般在二者的计数中得分都较低,表明词汇多样性较低、重复较多。整体上,我们发现多数测量方法表明这种小说模式有更多重复性,而且令人惊讶地指出这 个趋势似乎跨语言成立。[28]数据行与指定的类型标签呼应,数据列与预测的类型标签呼应。在汉语作品方面,分离也同样明显。(图1)
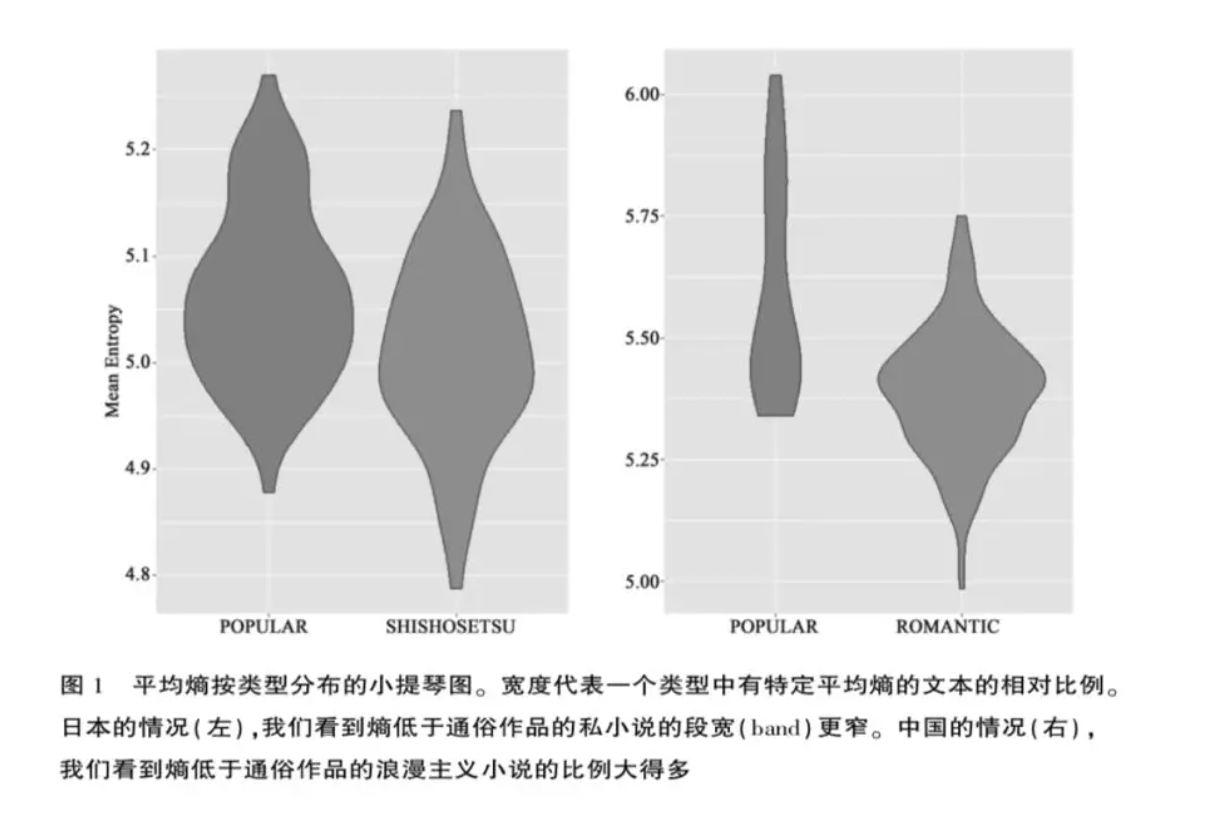
尤尔的K和吉罗的C也揭示出两种情况在统计学上的显著差异,反映出自我指涉小说词汇一致性和紧密型的倾向。[29]有趣的是,自我指涉小说也倾向于有更多重复性的极端波动,它们的TTR和熵的标准差更高也表明这点。这些文本平均来说更为重复,但也显示出在较少重复的段落和较多重复的段落之间更剧烈的转换。有个测量方法没有显示范畴间明显差异,即孔托伊阿尼斯的熵测量法,这表明没有哪个文本组比其他组有明显更广泛的依赖性。不过,与其他特征联合分析时,它确实有助于确认某些以词为基础的测量方式无法捕捉其重复方式的自我指涉文本,后面我们将回到这点。我们惊讶地发现,整体而言大多数测量方法都指向此种小说模式中更多的重复性,而且重要的是这一趋势似乎跨语言成立。
因为仅凭这些方法无法解释引起重复增加的可能原因,所以下一步我们就用粒度更细(finer-grained)的词汇和语法特征给它们做三角测量。也就是说我们为白话风格、语法结构和自我指涉的内容等高阶现象寻求额外的测算指标。包括明显的事物,如叙事模式(是否第一人称)、与思想感情相关的动词的比率。[30]也包括可能与西式语法和翻译作品的影响相关的特征:第一或第三人称代词的比率;标点符号比率;仅有句号的比率;语法功能词(停用词)比率。所有这些特征就本身而言,除了叙事模式,都证明是整体类型差异的可靠指标。考虑到私小说和浪漫主义小说的自白和唯我本质,我们推测代词和“思想/感情”动词都是如此,但是停用词(这些作品中更常见)和标点(较少)就不明显。至少在日本的情况中后者的一个可能原因在于这些作品包含的对话更少。[31]我们可以想象,自我沉思不会留给闲聊多少时间。比照我们对重复性的测量,将这些粒度更细的特征绘图,最有趣的发现是熵和表达沉思、感情和精神注意力的动词比率间存在相关。这个关系对日本和中国都成立,无论作品是第一人称还是第三人称,在每个类型内也成立。(图2)
比较私小说和浪漫主义小说文本中最冗余的100个段落和最不冗余的100个段落,揭示出最为冗余的段落中有些“思想/感情”动词尤其明显。[32]这些结果表明简单的词汇重复和认知表现之间的强相关。
确认重复是私小说和浪漫主义小说明确倾向的最后一步是将所有个体特征合为一个单独模型,以评估它们在区分这部小说和通俗作品时的相对权重。我们想知道,这样的模型,只靠熵、TTR、“思想/感情”词等测量方法,能多好地预测文本类型。使用有最佳子集选择(subset selection)的逻辑回归分类符(classifier ), 我们确认了我们在个体特征上看到的情况。[33]在日本的情况里,分类符猜到文本指定类型的准确率为样本的80%。事实上,它只需要孔托伊阿尼斯熵的测量法和思想/动作词比率、停用词和句号就实现了这一精确性。这不是说其他特征就没有辨别力,只是说明没有它们分类符也能表现得一样好。在中国这边,模型几乎每次都猜到正确类型(表1 ),只需要平均熵和尤尔的K就可做到。这里,只需词汇的冗余和一致性就足以分开两个语料库。不幸的是,和日本的情况不同,我们无法为语言差异做控制,这就很难确定重复性主要是语言效应,还是心理叙述的影响也起了作用。不过,两个结果都支持这个观点,即重复对于私小说和浪漫主义小说作家所做的实验而言至关重要。作为自我重复的冲动,汇集起来产生 了自我指涉写作类型的审美潮流看起来明显跨越了不同文化和语言语境。

注释:
[1] Hoyt Long, Anatoly Detwyler, and Yuancheng Zhu, “Self-Repetition and East Asian Literary Modernity, 1900-1930,” The Journal of Cultural Analytics, May 21, 2018. DOI:10.22148/16.022. Translated and reprinted with permission of the authors and The Journal of Cultural Analytics.
[2]中国方面参见 Robert Hegel and Richard Hessney,eds.,Expressions of Self in Chinese Literature (New York:Columbia University Press, 1985),尤其是 Leo Oufan Lee, “The Solitary Traveler: Images of the Self in Modem Chinese Literature”(282-307) ; Jaroslav Prusek,The Epic:Studies of Modern Chinese Literature (Bloomington:Indiana University Press, 1980);以及Lydia Liu, Translingual Practice: Literature, National Culture, and Translated Modernity—China,1900-1937 (Stanford: Stanford University Press,1995).日本方面参见 Karatani Kojin,Origins of Modern Japanese Literature, ed. Brett de Bary (Durham, NC:Duke University Press, 1993); James Fujii, Complicit Fictions:The Subject in the Modern Japanese Prose Narrative(Berkeley: University of California Press, 1993);以及 Janet Walker, The Japanese Novel of the Meiji Period and the Ideal of Individualism(Princeton, NJ:Princeton University Press, 1979).
[3]Edward Fowler, The Rhetoric of Confession:Shishosetsu in Early Twentieth - Century Japanese Fiction ( Berkeley:University of California Press, 1988),3.
[4]夏志清认为,除了少数代表性作家的作品,浪漫主义的唯一突出特质是“一味狂放……作品没有丝毫规矩绳墨,言过其实”。(译文摘自夏志清:《中国现代文学史》,刘绍铭等译,中文大学出版社2001年版,第82页)(“maudlin sentimentality... completely deficient in restraint and objectivity.”)见A History of Modern Chinese Fiction,Second Ed. (New Haven and London: Yale University Press, 1971),95.同样,李欧梵也断定浪漫主义很大程度上是借助丛书(group libraries)和性格冲突得以界定。见The Romantic Generation of Modern Chinese Writers(Cambridge, MA: Harvard University Press, 1973) , 22.
[5]Shimamura Hogetsu, ‘‘Jo ni kaete jinseikanjo no shizenshugi o ronzu” [ By Way of a Preface:On Naturalism and my Weltanschauung]. Cited in Fowler, 100.
[6]对这一评论的透彻分析,尤其对伊藤整(Ito Sei)、平野谦(Hirano ken)和小林秀雄(Kobayashi Hiedeo)的贡献,见Fowler, chapter 3 ;以及 Irmela Hijiya-Kirschnereit, Rituals of Self-Revelation:Shishosetsu as Literary Genre and Socio-cultural Phenomenon (Cambridge, MA:Council on East Asian Studies, Harvard University, 1996) , chapter 9.
[7]参见Tomi Suzuki, Narrating the Self:Fictions of Japanese Modernity (Stanford, CA: Stanford University Press, 1996) , 5-6.
[8]中国的情况参见Edward Gunn, Rewriting Chinese: Style and Innovation inTwentieth-Century Chinese Prose(Stanford: SUP,1991); Liu, Translingual Practice; Haiyan Lee, Revolution of the Heart: A Genealogy of Love in China, 1900-1950(Stanford: Stanford University Press, 2007); 及Raymond Hsu, The Style of Lu Hsun: Vocabulary and Usage(Hong Kong: Center of Asian Studies, University of Hong Kong Press,1979).日本的情况参见Fowler, Rhetoric of Confession; Hijiya- Kerschnereit, Riturals of Self-revelation;和Barbara Mito Reed, “Language, Narrative Structure, and the Shosetsu”(diss. Princeton University, 1988)
[9]Moretti, The Bourgeois:Between History and Literature (London:Verso, 2013), 19.
[10]中国的情况参见Liu and Gunn.日本的情况参见Kisaka Motoi, Kindai bunsho seiritsu no shoso[ Various Aspects of the Formation of Modem Style] (Osaka: Wazumi shoin, 1988),Chapter 3.书面日本语的方言风格和概念结构及语法结构转移之间的辨别,见Karatani, 49-51.通常认为 这二者是“言文一致”(genbun itchi)的新文学语言的发展中既有差异又有联系的两个运动。
[11]情节化方面,私小说曾被形容为“沉闷乏味”的描述,除了“某人的生活别无他物”(Yasuoka Sh6taro, 25); “片段、短促”(Yokomitsu Ri’ ichi52),或者个人体验的“随机”记叙(Kume Masao, 46); “用于私人表达的媒介,受损于对结构太关注”(Ito Sei, 63);还有,“一串印象主义的沉思”(Uno Koji,7)。上述引文全部引自Fowler.中国方面,郁达夫的作品被单挑出来用于强调“不完整的、无目地的、充满不确定的”旅程。引自Liu, 149,郭沫若对他一部作品的初期批评的著名回应:“将他的作品看作有开始、高潮和结尾的简单叙述是错误的——他是在试图 以梦的象征主义的形式表现无意识。”引自Liu,131.
[12] Reed, 144-169; Fowler, Chapter 2; and Liu, 153-54.
[13]实际上有人辩称冗余的水平甚至在所有语言中都很稳定。参见Marcelo A. Montemurro and Damian H. Zanette, “Universal Entropy of Word Ordering Across Linguistic Families.” In PLoS ONE 6(5) : el9875.
[14]Walter Ong,Orality and Literacy: The Technologizing of the Word[1982] (1991) : 35-40.
[15]Deborah Tannen,Talking Voices:Repetition, Dialogue, and Imagery in Conversational Discourse ( Cambridge : Cambridge University Press, 2007),49.最近一篇对文学中重复和口语风格研究的概述文章见Marissa Gemma, Frederic Glorieuz,and Jean-Gabriel Ganascia,“Operationalizing the Colloquial Style: Repetition in 19th - Century American Fiction,” in Digital Scholarship in the Humanities 2015 fqv066(doi: 10.1093/llc/fqv066),本文也是对这一工作进行定量扩展的极为出色的尝试。
[16]John Carroll, “Analysis of Verbal Behavior,” in Psychological Review 51 (March, 1944) : 102-119.
[17]Wendell Johnson, Language and Speech Hygiene:An Application of General Semantics, Outline of a Course (Chicago:Chicago Institute of General Semantics, 1939) , 11.
[18]可参见Wilhem Fucks的研究,他在1952年尝试将信息论用于文体测算,并比较了散文和诗歌中音节的熵。“On the Mathematical Analysis of Style,” in Biometrika 39, no. 9 (1952) :122-129.
[19] Gustav Herdan, Language as Choice and Chance (Groningen:P. Noordhoff, 1956) , 167.
[20]其他关于摘作为有效的词汇丰富性测量方法的评论文章,可见P. Thoiron, “Diversity Index and Entropy as Measures of Lexical Richness,” in Computers and the Humanities 20, no. 3 (1986):197-202;以及 David Hoover, “Another Perspective on Vocabulary Richness,” in Computers and the Humanities, 37, no. 2 (2003) :151-178.
[21]私小说语料库通过非原始的英文和日文来源创建,包括Fowler; Hasegawa Izumi, “Meijia·Taishoa . Showa shishosetsu sanjugo sen” [A Selection of 35 I-Novels from Meiji, Taisho, and Showa] , in Kokubungaku:kaishaku to kansho 27, no. 14 (1962) ;Wataskushi shosetsu handobukku [ The I-Novel Handbook],Aldyama Shun and Katsumata Hiroshi, eds. (Bensei shuppan, 2014).与私小说有关的作者的其他文本的选择是通过Nihon kindai bungaku daijiten(Encyclopedia of Modem Japanese Literature日本现代文学百科全书)辨识,基于其自传性内容的程度来选择。最后,还收入了几部标志性的自然主义风格文本,但并不被认为是私小说:例如德田秋声(Tokuda Shusei ’)的《粗暴》(Arakure)和有岛武郎(Arishima Takeo)的《某个女人》(Aru onna)。文本来自青空文库(Aozora Bunko)(日本的古登堡计划)或由我们自己数字化。通俗作品语料库从青空文库建立,包括类型作者的作品,如海野十三(Unno Juza)、甲贺三郎(Koga Saburo)、吉川英治(Yoshikawa Eiji)、中里介山(Nakazato Kaizan)和野村胡堂(Nomura Kodo)。可在本文所附的Datavers找到语料库作品标题完整列表和有关元数据。需要注意,为与中文的情况对等,我们用在本次实验中的比较语料库的种类因此受限,未来用同时期纯粹的现实主义小说与私小说作比较将很重要。本项目还创建了一个无产阶级小说语料库,但为了简化分析,不得不丢弃不用。
[22]浪漫主义语料库的核心是郑伯奇为影响深远的《中国新文学大系》第五集创造社文学卷所写的导论中提到的文本和作者。(郑伯奇编辑:《中国新文学大系》第五集,良友图书印刷公司1981年版)。在这部经典文集中,我们主要关注1925年之前的作品,以避免与“五卅惨案”后郭沫若开始提倡的政治化的、倾向大众的作品混杂。控制组语料库的核心基于“鸳鸯蝴蝶派文学”重要作品列表,参见魏绍昌编辑的《鸳鸯蝴蝶派研究资料》卷二(上海文艺出版社1962年版)。尽管如此,许多文本可能不是严格意义上的“鸳蝴派”派作品,而是更通俗的(商业上成功的)《三国演义》风格的历史演义小说。最初我们的项目目的是比较1930年代的浪漫主义小说、通俗小说和社会主义现实主义小说,但最后这个语料库证明难以根据重复的脉络与浪漫主义加以辨别,部分原因是1930年代的社会主义现实主义的文学风格受到“五四”时期风格发展的深刻影响。我们希望避免历时比较引起的影响问题,因而将社会主义现实主义语料库丢弃不用。将来研究中文类型相互作用的项目将包括这个社会主义现实主义语料库,还有鲁迅(其早期小说与浪漫主义同期)的作品、1920年代末和1930年代初所谓新感觉派的自恋体小说。
[23] I. Kontoyiannis, “The Complexity and Entropy of Literary Styles”, in NSF Technical Report, no.97 (June 1996-October 1997): 1-15.这种情况下它是非参数性的,因为没有和马尔科夫模型为基础的熵测量的较小的语境(一元模型,二元模型等)绑定。因此,对文本的单位(我们的研究里就是单独的字)序列中每个位置i来说,这个方法寻找始于位置i、不存在于i之前的最长序列。例如,在i=100的位置,它将寻找之前100个 字当中出现的最长的字序列。不同的i的长度用于估计整个文本的熵。
[24] 参见 George Yule, The Statistical Study of Literary Vocabulary [1944] (Hamden, CT: Archon Books, 1968). 测量计算如下:10,000×(M2 - M1) / ( M1 ×M1 ) . M1是单词类符的数量。给定序号频率上的单词数乘以序号的平方(例如,所有出现2次的词乘以22),然后所有数值相加得到M2。
[25] Juhan Tuldava, “Stylistics, Author Identificatio,” in Quantitative Linguistics: An International Handbook, ed. Reinhard Kohler, et. al (Berlin: Walter de Gruyter, 2005),374. 另见Arthur Holstein, “A Statistical Analysis of Schizophrenic Language,” in Statistical Methods in Linguistics 4 (1965): 10:14.
[26]Tuldava, 375. 吉罗的C是将最常用的50个词的频率相加再除以单词总数。
[27]关于尤尔的K和熵值测量方法的关系,参见 Kumiko Tanaka-Ishii and Shunsuke Aihara, “Computational Constancy Measures of Texts,” in Association for Computational Linguistics 41, no. 3 (2015): 481-502.
[28] 我们用成对的t检验和邦费罗尼校正来确定每个特征分布间的显著性。 显著性表明比较的两个样本中每个特征的均值并不相等,显著性在 p< = .05 水平上评定。
[29]中文情况中这两个测量方法不那么可靠,原因在于二者和长度更相关。这可能与中文语料库文本长度的变化大有关系,语料库包括一些非常短的文本和一些特别长的文本。
[30]我们计入的日语词如下:思、感じ、考え、心持、気分、心配、気持、考へ。我们计入的中文词如下:想、觉得、知道、心里、晓得、精神、想起、感到、觉、感觉、思想、感情。
[31]我们在中文情况中无法确定这点,因为有些通俗文本的OCR结果不太可靠,需要进一步校对,保证标点精确反映原始文本。
[32]为了确立特殊性,我们用卡方检验比较了 100个熵能最高的语块和100个熵能最低的语块中的词频。出现4次以下的词被排除。低熵私小说最特殊的思想/感情词是:考え(思考)和几个思う (思考)的词性变化,而浪漫主义篇章中它们是心(心/脑)和知道(知道),卡方测试值确认这些都位于前5%最特殊的词当中。
[33]逻辑回归分类器使用一套独立变量(此处即特征),从范畴上决定作品的类别(或类型)。它考虑这些特征在语料库子集中的分布,并确认它们在不同类型中是否差异显著。最佳子集挑选会尝试特征的每种组合可能性,以界定两组文本中最具区分性的组合。虽然在计算上难以处理十个以上的特征(即1000个组合),但我们还是得到了一个相对较小的特征集。我们用了一组不同的起始特征多次运行分类,“最佳”特征几乎总是相同,从而让我们对这一程序的可靠性有了信心。分类器用这些特征来确定之前未见过的作品的范畴。
主编: 陈静 责编: 顾佳蕙 美编:傅春妍


关注零壹Lab,获取更多数字人文信息!