零壹Lab | 远读、文学实验室与数字人文:弗朗哥∙莫莱蒂的文学研究路径
发布时间: 2018-10-09 杨玲
 公众号:lingyilab
公众号:lingyilab零壹Lab:记录数字媒介之日常,反思科技与人文精神
01Lab: Archiving digital lives, reconceptualizing sci-tech and the humanities
作者简介
杨玲(1972- ),湖北武汉人,厦门大学中文系助理教授,文艺学博士,主要研究方向为西方文论、文化研究。
弗朗哥∙莫莱蒂(Franco Moretti)是斯坦福大学英语和比较文学的讲席教授,并创立了斯坦福文学实验室(Stanford Literary Lab)。2014年3月,他的论文集《远读》(Distant Reading)因“提出了大胆而不同寻常的文学研究方法”获得美国“全国图书评论界批评奖”。[1]截止2016年,莫莱蒂已出版了七部英文专著,并主编了一部关于小说的百科全书《小说》(The Novel),在文学史、比较文学和数字人文等领域都做出了重要贡献。国内目前虽然已出现了多篇关于莫莱蒂的论文,[2]但尚未有人关注到文学实验室的运作情况,部分介绍还存在一定的误译和误读。[3]本文以莫莱蒂及其团队的学术发表为基础,结合相关书评、讨论和访谈,介绍了他利用定量(quantitative)和计算(computational)方法从事文学研究的主要思路和成果,并探讨了这些方法对于中国文学研究的启示。
莫莱蒂的文学研究有其独特的内在理路。由于大学期间深受意大利马克思主义哲学家德拉沃尔佩(Galvano Della Volpe)的影响,他一直对科学精神充满敬重,[4]并且从1980年代后期就开始探讨文学中的进化理论。莫莱蒂最初只是对文学形式的历史变化过程感兴趣,后来受著名进化生物学家恩斯特·迈尔(Ernst Mayr)的种形成(speciation)理论的启发,注意到地理在新形式的生成过程中的作用,因而转向制图学,开始制作文学地图,并在1990年代末出版了专著《欧洲小说地图集1800-1900》。[5]在从事文学地理学研究时,莫莱蒂意识到定量方法对地图制作的作用,又开始对计量史学产生了浓厚兴趣,并因此形成了“远读”的初步设想。[6]
在2000年发表的《关于世界文学的猜想》一文中,莫莱蒂不仅提出了著名的“世界文学体系”的假说,还同时提出了“远读”的概念。国内学者多关注前者,而忽略了后者。这两个概念其实是相辅相成的:前者重新规划了文学史的研究对象,后者则是针对新的研究对象所采用的研究方法。莫莱蒂认为,存在着一个可被划分为中心和边缘的、不平等的世界文学体系。我们无法用传统的细读(close reading,也可译作“近读”)方法来研究这一体系,因为细读是一种“神学操练”,它以极其严肃的态度对待极少量的文本,导致大量的文学作品从未被研究者阅读。如果想要理解“整个体系”,就必须采取远读的方法,聚焦“比文本小很多或大很多的单位:手法、主题、修辞——或文类和体系”。[7]
(一)小说的跨国兴起与文类周期
在2005年出版的《图表、地图和树:文学史的抽象模型》[8]一书中,莫莱蒂用三篇分别借鉴了年鉴派史学、地理学和进化论的论文,示范了远读的操作方法,并以此来说明远读关注的是“形状、关系、结构”以及“形式”和“模型”,距离不是障碍,而是“一种特定的知识形式”。[9]该书的第一篇论文《图表》已经初步运用了定量的研究方法。莫莱蒂在文中开门见山地重申了他对经典的怀疑,200部经典小说对于十九世纪的英国来说似乎已经够多了,但这个数字还不到英国19世纪出版的小说总量的1%。我们无法用阅读单个文本的方式来理解如此庞大的出版总量,“因为这是一个集体性的系统,必须用一种总体性的方式来把握”。[10]借助其他学者的统计数据,莫莱蒂首先用图表展示了英国、日本、意大利、西班牙和尼日利亚五国的小说发展史。从图中可以看出,五个国家都在不同的历史节点经历了类似的小说的兴起。在差不多20年的时间里,五国的小说出版量都出现了一个质的飞跃。莫莱蒂随后又用一些图表讨论了1740-1900年间英国小说类型的变化。通过查阅上百部研究资料,他整理出了一个包含44个小说文类的生存时间的图表(见图1)。从图中可以看到,这些文类大多以聚类(cluster)的方式出现和消失,160年间共有六次创造力的大爆发,每个类型的存活时间差不多都是25年。
尽管莫莱蒂无法解释文类周期性变化的成因,但他还是从这次量化研究中获得了独特的发现。大部分文学史家都会把抽象的小说(the novel)和各种小说(亚)文类当作两个不同的东西,然而图1中的44个文类却表明,小说不是作为一个单一的实体发展出来的,而是周期性地生成一整套类型。小说其实就是各种小说文类所构成的一个系统。在这个系统里,有些类型可能在形态上更加重要或更受欢迎,但它们绝对不是唯一存在的类型。当小说理论“将小说缩减为仅仅一个基本形式(现实主义小说、对话体小说、言情小说、元小说等等)”时,这就相当于把90%的文学史都抹杀掉了。[11]

图1 英国小说类型,1740-1900
(二)小说标题的大数据解读
弗吉尼亚大学教授维尔蒙(Chad Wellmon)将莫莱蒂的远读定义为“通过用计算和定量的方法分析海量的文本来研究文学史中逐渐显现的和长期的模式(patterns)”。[12]然而直到2009年发表的《风格公司:对7000个标题的反思(英国小说,1740-1850)》一文,莫莱蒂才算是真正发挥了大数据分析的威力。在这篇论文里,莫莱蒂选取了1740到1850年间出版的7000部小说标题作为量化分析的对象。因为标题是“作为语言的小说与作为商品的小说的交汇点”。[13]
在论文的第一部分,莫莱蒂运用平均数、中值(也称“中位数”)和标准偏差三个统计学概念,测量了7000部小说标题的长度。他发现,在18世纪中期,小说标题还是长短不一,长的标题可以达到40个词甚至更多,但是到了19世纪中期,长标题就彻底消失了,小说的标题也变得越来越相似。莫莱蒂认为,小说标题的这一变化与图书市场的变化息息相关。首先由于市场上新出版的小说数量的激增,一些杂志开始刊登新书的评论,使得相当于小说内容梗概的长标题变得多余。其次,短标题比长标题更能迅速而有效地吸引公众的眼球,并被读者记住。三是当时主要的图书市场,也就是流通性图书馆往往在其目录上对长标题实行简化,使得读者日益习惯短标题。
论文的第二部分对短标题的内容进行了量化分析。莫莱蒂发现短标题主要包括三个类型:专有名词;冠词+名词;冠词+形容词+名词的组合。另外还有一个小类型,概念性抽象。在冠词+名词这个类型里,几乎一半的标题都描述的是一种带有异国情调或越轨色彩的人物类型,如The Vampyre(《吸血鬼》)。当一个形容词被加到这个组合里时,情况就颠倒过来了,法基尔人或浪荡子之流从50%降到了20%,而妻子和女儿却从16%上升到40%,如The Unfashionable Wife(《老土的妻子》)。莫莱蒂对此的解释是,如果标题里只有一个名词,该名词就必须保证一个有趣的故事,吸血鬼因而就成了一个好的选择。多了一个形容词之后,即便是熟悉的人物也会被陌生化,而且形容词为标题引入了一个具有叙事功能的述谓成分。关于专有名词的标题,莫莱蒂也有一个独特的发现,在1820、1830年之前,那些含有女性名字的小说标题大多只有名,没有姓。这意味着这些小说的女主人公都是需要丈夫的未婚女性,小说的内容也都是围绕结婚情节展开的。此后,标题中的女主人公名字大多都包含了姓氏,如Jane Eyre(《简爱》),结婚情节被嵌入了成长小说或工业小说,女性也开始从私人领域进入公共领域。那些包含抽象概念的标题也经历了一个引人注目的变化。在1776到1880年间,这些与伦理道德相关的标题大多强调的是对道德规则的违反,如Disobidence(《不服从》), 但到了1800年之后,这些标题就开始强调道德的建构,如Self-Control(《自控》),这种对自我的规训暗示了维多利亚主义的萌芽。
(三)《哈姆莱特》的人物网络
在成功地运用量化文体学分析了小说的标题之后,莫莱蒂又在《网络理论,情节分析》一文中尝试用量化的方式来研究《哈姆莱特》的情节,因为他一直对哈姆莱特的朋友霍雷肖(Horatio)在剧中的作用感到困惑。然而,故事情节的量化远比莫莱蒂预想得困难,他不得不从定量研究退回到定性研究。尽管量化失败,但莫莱蒂还是借助网络理论[14]的基本概念,以视觉化的方式呈现了《哈姆莱特》中被忽略的人物和空间关系。复杂网络理论研究的是一大组对象之间的关系,这些对象被称为节点或顶点(nodes or vertices),它们可以是任何人或物,对象之间的联系被称为边(edges,也译作“连线”)。通过分析节点与边的连接方式,可以揭示大型系统的许多令人意想不到的特点。莫莱蒂将复杂网络理论移植到对叙事的分析,把《哈姆莱特》中的每一个人物定义为节点,只要两个人物之间说过话,就当作是一个边,根据这个方法生成了一个最基础的人物网络图。[15]
莫莱蒂认为,通过借助网络来思考情节,把叙事的时间转化为网络中的空间,可以有以下几个收获。首先,过去发生的事件与当下的事件一样获得了可见度。其次,整体情节中的某些特定“区域”(region)变得可见。比如,《哈姆莱特》中有一个死亡区域(见图2中的标红区域),所有的死亡和悲剧都发生在这个以国王和王子为轴心的区域里。第三,人物网络是一个抽象的模型,它如同X光一样,可以让我们探测到隐藏在剧本背后的结构。如我们可以发现主人公其实就是网络的中心。哈姆莱特之所以是同名悲剧的主角,乃是因为他和剧中所有的人物都很近,平均只有1.45度的距离。第四,我们还可以利用这个模型来进行推演和实验,比如在网络图中抽出国王克劳狄斯,整个网络基本完好无损,抽出哈姆莱特,整个网络几乎分裂成两半,如果同时去掉哈姆莱特和霍雷肖,整个网络就彻底碎片化了,《哈姆莱特》也将不复存在。由此可见,主人公的重要性不在于其本身的特质,而在于他/她对网络的稳定性所起的作用。霍雷肖是剧中一个不可或缺的角色,因为他联系着绅士、水手、大使等一系列边缘人物,这些边缘人物指向的是丹麦京城艾尔西诺之外的世界,正处于萌芽状态的欧洲国家体系(state system)。霍雷肖这个没有动机、没有目的、没有情感、也没什么台词的扁平人物,其实就是官僚国家的象征。通过一系列的人物网络图,莫莱蒂对《哈姆莱特》做出了令人耳目一新的解读。
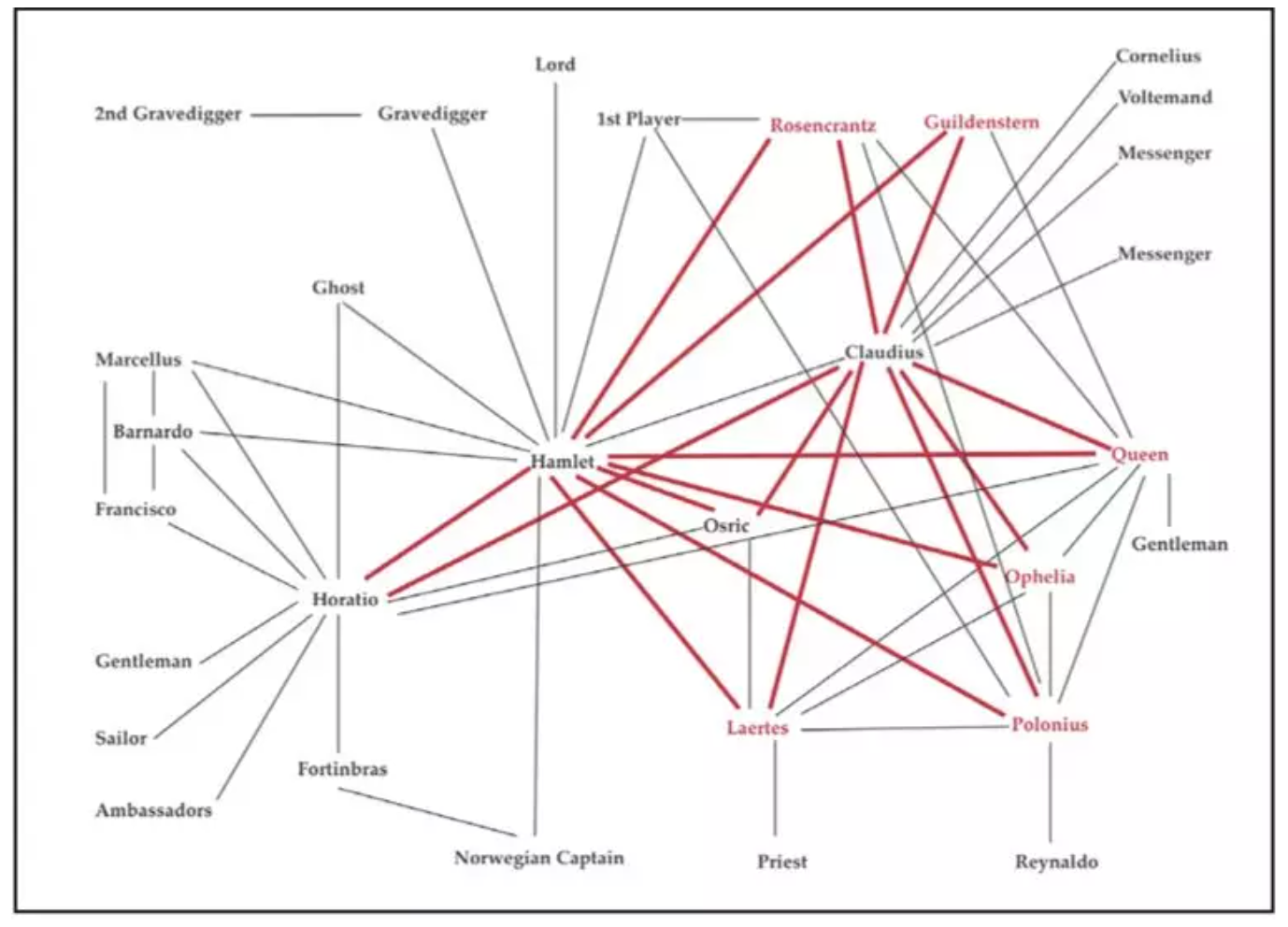
图2 《哈姆莱特》的人物网络图,红色区域为死亡区域。
近年来,文本挖掘等数字人文技术的发展和认知科学关于阅读体验的新见解,对以文本细读为主的传统文学研究方法带来了前所未有的挑战,“如何阅读”这个本来不是问题的问题,开始变成了一个大问题。[16]莫莱蒂提出的远读概念,可谓是生逢其时。尽管远读算不上一个完整的理论体系,只是一些为了解决特定问题而设计的实验性方法,但它至少让人们看到文学研究除了细读,还可以有别的玩法。远读的这套方法也恰好顺应了欧美的数字人文风潮。[17]《图表、地图、树》和《远读》出版之后,都在学界引起热议,以至于莫莱蒂被称为“当今英文和比较文学领域最具争议性的人物”。[18]
2010年,莫莱蒂与马修∙乔克思(Matthew L. Jockers)一起共同建立了文学实验室,尝试用科学研究中的协同合作方式来开展文学研究。在传统的文学研究模式里,“一个有资格(如获得博士学位,或正在攻读博士学位)的作者”产生了一个原创性的想法,将其应用到一个文本或一些问题上,然后完全依靠个人的力量生产出一个新的文本。[19]但文学实验室却创立了一个类似科学实验室的环境,“一种让个体退到背景,让实验本身移到前景的工作方式”。[20]在第一篇集体合作的研究论文遭到学术期刊的婉拒之后,莫莱蒂和实验室成员决定以“小册子”(pamphlet) 的形式,将研究成果公开发表在实验室的网站上。目前,实验室已经发布了12篇小册子,这里仅介绍莫莱蒂参与的三个集体研究项目。
(一)词语与文类识别
2011年,莫莱蒂与博士生艾莉森(Sarah Allison)等人合作发布了实验室的第一个小册子《计量形式主义:一个实验》,探索了如何用计算机算法来为文学文本确定文类归属。[21]这项研究的缘起是,莎士比亚专家维特摩尔(Michael Witmore)向莫莱蒂介绍了他用Docuscope[22]识别莎士比亚戏剧类型的工作。为了了解同样的技术是否也能用来识别小说类型,莫莱蒂邀请维特摩尔来斯坦福做了一个文类配对实验。维特摩尔通过Docuscope技术只弄错了哥特小说和历史小说这两个文类,其他两组文类皆匹配成功。由于哥特小说和历史小说的文类边界本来就不甚清晰,这个结果可说是相当不错。随后,乔克思也尝试用一个包含44个单词和标点符号的特征集(feature set)来识别文类,结果和Docuscope的成绩一样好。这些词后来被实验室命名为“最常见词语”(Most Frequent Words,简称MFW)。
计算机证实了文学研究者的一个普遍共识,即某些文本是可以归于同一个类型的,但计算机究竟是怎样分类的呢?维特摩尔向项目组成员展示了Docuscope分离出的一个最具哥特风格的文本字段。令人震惊的是,计算机识别的哥特风格特征与读者识别的特征完全不同。计算机捕捉到的是代词和过去时态,而读者则是通过文本中“被压制的恐惧”、“不安”、“废墟”、“颤抖的双腿”等词语判断出这是一部哥特小说。项目组成员意识到,文类如同楼房一样,在砂浆、砖块和建筑等每一个可能的分析尺度(scale)上都拥有一些独特的特征。MFW识别的是砂浆,Docuscope的词汇-语法范畴识别的是砖块,而读者识别的则是整个建筑。这三个层面没有任何交集,它们给出的文类标记也彼此不同。
然而,当项目组试图通过主成分分析[23]把文类系统从五花八门、互不相干的范畴[24]整合成由相互关联的形式变量构成的单一矩阵时,却遭遇到挫折。原因是文类是由风格标志和叙事标志(如情节)共同构成的,二者同等重要,而Docuscope和MFW主要是用来识别语言的。在缺乏识别情节的计算工具的情况下,文类识别的结果自然不可能准确。Docuscope和MFW实际上更适用于辨识同一个作者创作的不同文类的作品。因为一个作者即便创作出多种不同类型的作品,其语言风格也不会发生大的变化。这个持续了一年的研究项目虽然没有取得突破性的成果,但至少让莫莱蒂和团队成员迈出了实验性研究的第一步。
(二)句子与风格
2011年4月,实验室召开了一个年度工作总结会议。在会上,实验室成员再次讨论了第一个小册子《计量形式主义》,认为这项研究的真正对象也许是风格,句子则是风格的最基本单位,正是在句子层面,风格作为一种独特的现象获得了可见度。莫莱蒂随后和五名学生一起开展了一个关于小说句子的计算研究,并于2013年发表了实验室的第五篇小册子《句子尺度的风格》。[25]
项目组用Chadwyck-Healey19世纪小说数据库里的250部英国小说作为语料库,重点研究了叙事性句子。他们发现叙事性句子主要有三个类型:包含两个独立性从句(independent clause, 简称IC)的IC-IC类句子、一个独立性从句接一个非独立性从句(dependent clause,简称DC)的IC-DC类句子、以及一个非独立性从句接一个独立性从句的DC-IC类句子。通过从表达并列、转折、限定、顺序等多种逻辑-语义关系的连词入手,项目组注意到,IC-DC类句子主要涉及述谓和限定,较少涉及顺序。比如,P. B. 雪莱的一个句子:“Her extreme beauty softened the inquisitor who had spoken last”(她极度的美貌软化了最后说话的审问者)。在这个句子里,非独立性从句一方面引出了一个不同于主句主语的新人物(审问者),同时又赋予了这个新人物在文本中极为有限的作用。从句自然地滑入了一种叙事性衰减。而在 DC-IC类句子中,相反的情况出现了,位于主句之前的非独立性从句常常报告了一个准备性的事件,而主句则包含了更出人意料的事件。比如拉德克利夫的一个句子:“While she looked on him, his features changed and seemed convulsed in the agonies of death”(当她看着他,他的五官变了,似乎在死亡的痛苦里抽搐)。随着主语从“she”转为“his features”,叙事强度也增加了。也就是说,IC-DC类句子代表了叙事系统的收缩和衰减,DC-IC类句子则代表了扩张和强化。而在IC-IC类句子中,两个从句之间是重复或稍加解释的关系,叙事达到了一种静止状态。如狄更斯的一个句子:“Oh she looked very pretty, she looked very, very pretty!”(哦,她看上去非常漂亮,她看上去非常、非常漂亮!)
在发现了句子形式与逻辑关系和叙事节奏之间惊人的相关性之后,项目组又开始思考是否也能在句法和语义之间建立起某种联系。他们首先计算了所有句子中单词的平均(或称“预期”)出现频次,然后计算了这些单词在每一种句子类型中的实际出现频次,从而找出了那些显著高于预期的词语,也就是“最特别的词语”(Most Distinctive Words),最后又将这些数据用主成分分析方法视觉化。研究人员发现DC-IC类句子有一个稳定的模式,即它的非独立性从句中往往会包含一个空间运动,而它的独立性从句(或主句)则多和情感有关。比如,在“When the procession came to the grave the music ceased”(当队伍来到坟墓时,音乐停止了)这个句子里,独立性从句中先发生了一个空间运动(来到坟墓),然后才发生了其他的事情,空间运动成了叙事发展的跳板。而在“When the ceremony was over he blessed and embraced them all with tears of fatherly affection”(仪式结束后,他噙着饱含父爱的泪水,祝福和拥抱了所有人)这个句子里,主句中的叙事强化依靠的是情感,而非行动或事件。
施皮策(Leo Spitzer)和奥尔巴赫(Erich Auerbach)等文论家在讨论风格时,关注的都是段落和整个文本。莫莱蒂团队则通过研究从句的组合方式,提出了一个新的风格概念,将风格定义为“一个句子里各种分离的元素的浓缩(condensation)”,一种句法-语义性的浓缩过程。这种浓缩既是对某种规范的偏离,同时又是重复性的,通过一定量的重复形成了一种模式。风格从属于各种不确定的偶然性,它不是必然出现的。然而,当风格出现时,它会立即变得典型和可识别,能够以最直接和最不含糊的方式区分一个作者、一个文类、或一个文学运动。更重要的是,这个句子层面的风格概念是一个具有可操作性的概念,构成风格的元素是可以被计算机程序收集和测量的。[26]
(三)文学经典的量化分析
数字人文方法到底给文学研究带来了哪些新的发现?当研究对象从经典转变为档案之后,会让文学研究有很大的改观吗?“经典”和“档案”这两个词到底意味着什么呢?实验室2016年发布的《经典/档案。文学场中的大规模动态》一文就旨在回答这些问题。[27]
莫莱蒂和项目组成员首先想到了布迪厄在《艺术的法则》一书中提供的一张关于19世纪末法国文学场的图。这张图根据成圣程度和经济效益两个指标展示了19世纪末各种文类和文学运动在文学场中的位置。尽管这张图影响力很大,但由于缺乏明确的、可测量的标准,它并没有真正成为一个可供其他学者复制的研究工具。为了对经典进行量化研究,项目组设计了两个可供量化的标准:人气(popularity)和声望(prestige)。人气的计算依据的是作家的作品在19世纪英国的重印次数和翻译成法语和德语的次数,声望则是依据作家在MLA(美国现代语言协会)参考文献数据库中被提及的次数,以及在DNB(《牛津国家人物大辞典》)中的词条的长度。根据这两个数据,项目组绘制出了一个18到19世纪英国小说场域图。这个小说场由三个部分构成(见图3)。靠近纵轴的三角区域里的作家,其声望值比人气值至少高出两倍,靠近横轴的三角区域里的作家人气值比声望值至少高两倍。位于中间区域的作家,其声望值和人气值相互持平。我们熟知的19世纪英国经典作家大多位于中间区域,如笛福、理查逊、菲尔丁等。也就是说,布迪厄关于经典是“颠倒的经济世界”的观点并不准确。声望与人气并不必然对立,声望似乎就是从人气中发展出来的。通过把经典的概念分解为人气和声望(或市场和学院接受度)这两个基本要素之后,我们可以看到经典并不是一个具有自主性的概念,而是对立力量互动的随机结果。

图3 英国小说场,1770-1830.横轴代表人气,纵轴代表声望。
不过,项目组并不满足于像布迪厄那样进行文学社会学的研究,作为文学史研究者,他们还想知道小说的经典化过程是否和它们的形态特征有关。在项目的第二阶段,研究人员测量了语料库中的信息冗余程度。人们普遍认为读者偏好能提供丰富信息的文本,而不是有大量冗余信息的文本。因此,前一类文本会成为市场上的常青树,而后者则会被市场淘汰。一个二阶信息冗余(second order redundancy)的测试结果表明,[28]四分之三的经典文本所包含的冗余信息都比四分之三的档案文本(即非经典文本)要少得多。常识似乎是对的,经典文本的确包含了比档案文本更丰富的信息。为了验证这个结果,研究人员又使用了测量词汇丰富程度的语言学工具类符形符比。[29]如果一个文本的冗余性越低,那么它的词汇就应该越丰富。然而,测量的结果却令人困惑,经典文本从整个文本的词对(word pairs)的角度看,要比档案文本更丰富,但从单个词的角度看,经典文本比档案文本冗余性更强。奥斯汀、狄更斯、艾略特的作品的类符形符比都低于平均值。通过部分文本片段的细读,项目组发现,经典文本的冗余性与这些文本所描绘的创伤性事件、情感强度或口语形态(orality)有关,而类符形符比高的档案文本普遍体现出一种语言保守主义,喜爱用书面语,卖弄文藻,甚至还夹杂了来自其他文类的材料。比如,韦斯特(Jane West)就在她的作品里大量使用了诗歌、复杂的比喻和仿作(pastiche)。
在论文的结语部分,项目组对巴赫金小说理论的两个关键概念复调(polyphony)和杂语(heteroglossia)做出了修正。巴赫金认为复调和杂语是密切相关的,但项目组的研究结果却表明,复调和杂语实际上位于小说场中对立的区域。复调倾向于和经典文本联系在一起,而杂语则是那些失败的档案文本的特点。巴赫金认为,当小说与其他话语(discourse)发生接触时,小说会吸取那些话语的长处,从而强化自身在文化系统中的核心地位。然而,对历史、哲学、政论、旅行报道等其他话语的吸收,也可能产生负面影响,导致小说叙事活力的丧失。19世纪大量被遗忘的作家就是活生生的例子。因为当时英国小说形式的总体发展方向是“拧紧自己内在的叙事螺栓,而不是从外部话语寻找灵感”。[30]
尽管斯坦福文学实验室现已成为美国数字人文领域的重要机构之一,但莫莱蒂本人并不迷信数字人文。在他看来,数字人文不过是“数字时代针对文学和文化史的科学的、解释性的、经验性的、理性的……研究路径所采取的形式”。[31]数字人文研究目前仅仅提供了一个新的、比传统文学经典大得多的档案和新的、更快的计算程序,但它还缺乏新的概念,缺乏一个像什克洛夫斯基的《艺术作为技巧》、罗兰•巴特的《论拉辛》、或萨义德的《东方主义》那样的主要理论宣言。只有理论框架、阐释模式的变化才能让文学研究发生根本的变化。[32]如果数字人文做不到这一点,其价值就将始终存疑。
莫莱蒂尤其反对数字人文领域盛行的头脑简单的实证主义和数据驱动(data-driven)的研究方式。他援引库恩(Thomas Kuhn)的观点认为,仅仅通过检视数据,是不可能发现新的自然规律的。正确的做法应该是从理论出发,通过测量和数据,加强理论和现实之间的联系,把理论所蕴含的潜在(potential)秩序转换成实在(actual)秩序。理想的数字人文研究应是理论驱动的(theory-driven)、数据丰富的,不仅能够检验、证伪、挑战现存的文学研究知识,还能够创造出新的文学概念。[33]莫莱蒂和实验室成员通过计算研究对奥尔巴赫、巴赫金、布尔迪厄等权威学者所提出的文学理论的验证和修订,他们将“经典”、“风格”等模糊的文学概念变得可操作、可计量的努力,都是在朝着这个理想迈进。
当代中国文学研究似乎正面临新一波阅读/阐释的焦虑:一方面强烈质疑西方文学、文化理论,渴望建立本土的学术话语,与西方学界分庭抗礼;[34]另一方面则是在阐释本土新兴文学现象时捉襟见肘、力不从心。尤其是浩如烟海、动辄数百万字的网络文学作品,常常让习惯文本细读、精读的学院派研究者既“读不过来”又“读不下去”,甚至发出“研究网络文学的难度比研究传统文学要大”的感喟。[35]解决这种困境的方法,或许并不是急着拒斥西方理论,而是更全面、更深入地了解西方文学研究的各种理念和方法。在笔者看来,莫莱蒂及其研究团队的工作至少为中国文学研究提供了三个方面的方法论启示。
首先是展示了定量或数字人文方法在文学研究中的价值和作用。尽管国内文学研究者关于数字人文的讨论才刚刚起步,但已经产生了显著的分歧和争议。张江教授在《强制阐释论》一文中提出,在“大数据、云计算的网络时代里”,用于建构文学理论的统计方法“应该大有所为”。[36]他的这一观点随即遭到了张玉能教授的质疑。后者认为,“文本统计学的定量分析,对于文学的定性分析的证实或者证伪的功能”极为有限,文本统计学的数据也无法“参与到理论建构的工作中去”。[37]还有一些学者虽然肯定了定量方法在文学研究中的可行性,但他们也对利用客观方法来研究主观性较强的文学作品持一定的怀疑态度,[38]或是主张仅利用数据统计方法来研究文学的传播和接受,如调查哪些主题、情节和语言风格最受读者欢迎。[39]莫莱蒂及其文学实验室的工作表明,文学领域的计量研究并不仅仅是词频统计那么简单,而是一种以理论概念和假说为指导的、以数据库、定量和计算方法为核心的、以跨学科的研究团队为主体的一套复杂而严谨的科学研究模式。这种被统称为“数字人文”的研究模式不仅能够生产出新的、有效的知识和洞见,还能够促进理论的修正和重构。
特别值得注意的是,莫莱蒂坚持用数字人文方法来研究文学本体,甚至在文学实验室发表的首个小册子里将项目组的研究方法命名为“计量形式主义”(quantitative formalism)。在莫莱蒂看来,形式分析“是任何新的方法——定量的、数字的、进化的、或不管什么方法——必须借此证明自我的领域”。任何新的文学研究方法不仅必须证明它能够完成形式分析,而且还要证明它比现有的分析方法做得更好,或至少同样好。[40]莫莱蒂认同卢卡奇在《小说理论》中提出的一个观点,即“每个形式都是对一种根本性的生存失调(dissonance)的解决之道”。随着时间的流逝,这些失调都已经不复存在,但文学却将它们保存起来。通过形式分析,我们可以理解过去的文学作品所曾经试图解决的失调,从而揭示出历史不为人知的一面。[41]
其次是展示了如何利用数字人文来进行小说、戏剧等叙事文体的研究。或许是由于各类古籍数字化项目的推动和数据库的便利性,国内学者在尝试数字人文方法时,往往偏爱古代诗词文本。古代文学研究者对于数字人文的兴趣也远大于现当代文学研究者。[42]尽管不乏运用检索软件和应用语言学统计方法来分析中文小说文本的例子,[43]但其研究视野、技术含量和理论意义一般都较为有限,得出的结论也往往只是佐证了现有的学术观点。莫莱蒂及其团队在研究小说的文类、主题、人物、情节、风格等要素时所采用的数字人文方法,对于中国网络文学研究具有特别的借鉴作用。众所周知,自1990年代以来,小说已经成为当代中国文学的主导形式,网络文学中的超长篇小说更是发展为文化创意产业的重要源文本。近年来,一些学者开始以对待纯文学的严肃态度来研究网络文学,强调进入网文现场。如邵燕君教授主编的《网络文学经典解读》,就以文本细读的方式对十三位知名网络作家的作品进行了深入分析。不过,既然网络文学的“网络性”已经瓦解了“雅俗二元对立结构”,[44]研究者为何还要将极少数网络文学作品经典化,人为地制造出一个更接近高雅文化标准的精英网文作者阶层?那些少人问津的网络文学作品是否就对网络文学的整体发展毫无益处?如果摈弃以经典为对象的传统文学研究方法,我们又该如何面对海量的网络文学作品?
将网络文学的研究单位从个别作家、作品扩大到文类和网站(社群)或许是一种可能的替代性选择。比如,与其用细读的方法来研究辛夷坞的言情小说,不妨用远读的方法来探究整个言情小说文类。指出辛夷坞的言情小说“常常出现违背伦常的恋情”,通过制造禁忌来重建爱情神话,[45]固然不错,但我们还需要考虑这种情节模式是否也广泛见于其他都市言情小说。我们或可借助文学网站自带的庞大数据库,用主题模型的方法,以更充分、更精确的数据来证实这种禁忌性恋情到底是言情小说新近出现的一个发展趋势,还是反复重现的母题,建构(重建)爱情神话是否是言情小说这一文类区别于其他文类的根本特点?在借鉴莫莱蒂的研究方法的同时,我们还可以用网络文学的发展史来验证他的一些研究结果。比如,关于文类周期的问题。网络小说的类型化究竟是如何发生的?这些类型是否如莫莱蒂所说的成群结队的出现然后集体消失?还是会不断地与其他文类融合,衍生出新的变种。就目前网络文类的发展状况而言,似乎后一种判断更加准确。[46]
除了上述两个方面,莫莱蒂的研究中最值得借鉴、也最难借鉴的,恐怕还是他对统计数据的分析和阐释能力,他通过微观的数据推导出宏观的结论的能力。定量方法之所以一直没能在中国学界产生大的影响,恰恰就因为国内从事定量研究的学者缺乏莫莱蒂那样的理论视野和学术积累,无法从数据中提炼出具有普适性和启发性的理论思考。以小说标题为例,国内其实已经有学者做过相关的定量研究。陈海英曾“选取国内知名文艺杂志的文艺作品、历年茅盾文学奖和鲁迅文学奖的获奖作品及一些有影响的影视作品名称”,自建了一个包含2000个标题的语料库,并从中随机抽取了1200个标题进行统计分析。[47]和莫莱蒂一样,她也统计了标题的字数和语言结构,但却止步于对标题的结构性分类,没能像莫莱蒂那样从小说标题的语言学信息中解读出文学市场的变化、文类的变化与整个社会文化的变迁,其研究价值也因此大打折扣。
从细读到远读、以及数字人文的方法论转型,或许能为中国的文学研究开创一个新的时代,为研究者提供更好地介入、把握本土文学实践的工具,并最终“通过大数据走向大问题”,[48]让文学研究中的中国理论、中国学派不再是一个遥不可及的梦想。
注释
[1]http://bookcritics.org/blog/archive/national-book-critics-circle-announces-award-winners-for-publishing-year-20。
[2]截止2016年7月,CNKI数据库中专门论述莫莱蒂的期刊论文有:吴雨平、方汉文:《“新文学进化论”与世界文学史观——评美国“重构派”莫莱蒂教授的学说》,《文艺理论研究》2013年第5期;吴雨平、方汉文:《“文学世界体系”观念评骘》,《外国文学研究》2013年第5期;高树博:《小说对城市的想象》,《重庆广播电视大学学报》2014年第4期;高树博:《论弗兰克·莫莱蒂进化论文学史观》,《绵阳师范学院学报》2014年第10期;高树博:《弗兰克·莫莱蒂对“细读”的批判》,《学术论坛》2015年第4期;陈晓辉:《大数据时代的文学研究方法——基于弗兰克·莫莱蒂文学定量分析法的考察》,《文艺理论研究》2016年第2期;陈晓辉:《弗兰克·莫莱蒂的进化论马克思主义形式观》,《中国图书评论》2016年第3期;陈晓辉:《弗兰克·莫莱蒂的三重文学空间观》,《西北大学学报》2016年第3期。其他值得关注的论文包括:金雯和李绳的《大数据分析与文学研究》(《中国图书评论》2014年第4期)以及梅新林的《论文学地图》(《中国社会科学》2015年第8期)。前者有助于了解莫莱蒂所处的学术语境,后者将莫莱蒂的研究放入了欧美文学地理学的思想脉络。
[3]比如,莫莱蒂的论文“Conjunctures on World Literature”已由诗怡翻译成中文,并发表于《中国比较文学》2010年第2期。这篇中译将文中的重要概念“distant reading”(“远距离阅读”或“远读”)译成了“远离阅读”。陈晓辉的《大数据时代的文学研究方法》一文也存在一些误译。
[4]Franco Moretti, Graphs, Maps, Trees: Abstract Models for a Literary History, London: Verso, 2005, 2. 在2016年的一个访谈中,莫莱蒂透露他年轻时的理想是做一名物理学家,因为数学不够好,才选择了文学。
[5]Franco Moretti, Distant Reading, London: Verso, 2013, 179.
[6]Melissa Dinsman, “The Digital in the Humanities: An Interview with Franco Moretti,” Los Angeles Review of Books, March 2, 2016, https://lareviewofbooks.org/article/the-digital-in-the-humanities-an-interview-with-franco-moretti/.
[7]Franco Moretti, Distant Reading, pp. 48-49.
[8]该书中的“树”指的是进化树图,因此有学者将书名译作“图表、地图、树状图”。考虑到科学界通常不在“树”后面加“图”字,如“系统树”、“决策树”,本文译作“树”。
[9]Franco Moretti, Graphs, Maps, Trees, 1.
[10]Franco Moretti, Graphs, Maps, Trees, 4.
[11]Franco Moretti, Graphs, Maps, Trees, 30.
[12]Chad Wellmon,“Sacred Reading: From Augustine to the Digital Humanists,” The Hedgehog Review 17.3 (Fall 2015), http://www.iasc-culture.org/THR/THR_article_2015_Fall_Wellmon.php.
[13]Franco Moretti, Distant Reading, 181.
[14]网络理论涉及社交网络、信息网络、科技网络、生物网络等多个方面,最为人熟知的就是小世界理论或六度分隔理论。
[15]莫莱蒂在文中坦承,这个图存在两个缺陷,一是没有考虑边的权重(weight),两个人物之间说一句话和说一百句话,都被当作是一回事。二是没有标识出言语行为的方向,没有说明是谁对谁说话。直到2013年发表的“‘Operationalizing’: or, the Function of Measurement in Modern Literary Theory”一文,莫莱蒂才找到了满意的解决方案。
[16]Andrew Seal, “We Have Never Been Well-Read: Franco Moretti's Pact with the Devil,” The Quarterly Conversation 33 (September 2, 2013), http://quarterlyconversation.com/we-have-never-been-well-read-franco-morettis-pact-with-the-devil.
[17]参见Matthew G. Kirschenbaum,“What Is Digital humanities and What’s It Doing in English Departments?”ADE Bulletin 150(2010):1-7;陈静:《历史与争论——英美“数字人文”发展综述,《文化研究》2014年第2期。
[18]Rachel Serlen,“The Distant Future? Reading Franco Moretti,” Literature Compass 7.3 (2010): 214-25.
[19]Stanley Fish, “The Digital Humanities and the Transcending of Mortality,” January 9, 2012, http://opinionator.blogs.nytimes.com/2012/01/09/the-digital-humanities-and-the-transcending-of-mortality/.
[20]Karen Shook, “The Author,” The Times Higher Education Supplement, June 27, 2013, https://www.timeshighereducation.com/books/the-bourgeois-between-history-and-literature-by-franco-moretti/2005020.article.
[21]Sarah Allison, Ryan Heuser, Matthew Jockers, Franco Moretti, and Michael Witmore, “Quantitative Formalism: An Experiment,” January 15, 2011, https://litlab.stanford.edu/pamphlets/.
[22]Docuscope是美国卡内基·梅隆大学开发出来的一种文本分析技术,相当于一部智能字典,包含了超过2亿的英语词串(string)和101个被称为“语言行动类型”(Language Action Types,简称LATs)的功能性语言范畴,每个词串都被赋予了一个LAT。Sarah Allison, et al., “Quantitative Formalism,” 2. 国内对Docuscope的应用,参见胡咏梅、王建东:《基于Docuscope技术上非英语专业学生描写文写作研究》,《佳木斯教育学院学报》2010年第2期。
[23]主成分分析(Principal Component Analysis)是利用降维的思想,把原来多个变量转化为少数几个综合变量(即主成分)的一种统计分析方法,其中每个成分都是原始变量的线性组合,各主成分之间互不相关,从而使这些主成分能够反映原始变量的绝大部分信息,且所含的信息互不重叠。
[24]目前英语小说的文类名称相当混乱,有的源自小说媒介,如书信体小说;有的源自小说内容,如历史小说、工业小说;有的来自风格,如自然主义小说;有的用比喻,如哥特小说、银叉小说(silver-fork)。Sarah Allison, et al., “Quantitative Formalism,” 10, note 12.
[25]Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, Amir Tevel and Irena Yamboliev, “Style at the Scale of the Sentence,” June 2013, https://litlab.stanford.edu/pamphlets/.
[26]Sarah Allison, et al., “Style at the Scale of the Sentence,” 26.
[27]论文将档案定义为“所有已出版的文学作品中被图书馆或其他地方保存下来的部分”。论文考察的经典文本来自Chadwyck-Healey19世纪小说数据库,共计 263部作品,档案文本总共854部,来自各种不同的渠道。参见Mark Algee-Hewitt, Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, and Hannah Walser: “Canon/Archive. Large-scale Dynamics in the Literary Field,” January, 2016, 2-3, https://litlab.stanford.edu/pamphlets/.
[28]项目组测量了每一个单词与下一个单词的衔接的可预测性。比如,“of”这个单词后面通常接的都是“the”,而不是 “no”,因此“of no”这个二元组合(bigram)就远比“of the”更难预测,包含的信息量也更大。
[29]类符形符比 (type-token ratio)指的是不同的词形或类型的数量与单词或形符的关系。
[30]Mark Algee-Hewitt, et al. “Canon/Archive,” 12.
[31]Melissa Dinsman, “The Digital in the Humanities.”
[32]Franco Moretti, “Invisible objects,” https://www.wiko-berlin.de/en/fellows/alumni/fellows-club/newsletter/may-2014/franco-moretti-invisible-objects/.
[33]Franco Moretti, “‘Operationalizing’: or, the Function of Measurement in Modern Literary Theory,” December 2013, 4, 13, https://litlab.stanford.edu/pamphlets/.
[34]如2014年以来围绕张江教授的“强制阐释”论所展开的学术辩论,相关梳理参见魏建亮:《关于“强制阐释”的七个疑惑》,《山东社会科学》2015年第12期。
[35]周志雄:《网络文学的发展与评判》,人民出版社2015年版,第329页。
[36]张江:《强制阐释论》,《文学评论》2014年第6期。
[37]张玉能:《本体阐释论质疑——与张江教授商榷》,《上海文化》2015年第12期,第17页。张玉能教授对统计学的理解还停留在随机抽样的阶段,他所援引的《科学哲学导论》一书源自鲁道尔夫·卡尔纳普1958年发表的系列演讲。然而,在当下的大数据时代,由于具备了强大的数据处理能力,我们已经不需要依靠采样分析,而是可以“选择收集全面而完整的数据”,“从不同角度,更细致地观察和研究数据的方方面面”。参见[美]维克托•迈尔-舍恩伯格、肯尼思·库克耶:《大数据时代:生活、工作与思维的大变革》,盛杨燕、周涛译,浙江人民出版社2013年版,第37-42页。
[38]陈晓辉:《大数据时代的文学研究方法——基于弗兰克·莫莱蒂文学定量分析法的考察》,《文艺理论研究》2016年第2期。
[39]徐杰:《大数据时代的新媒体文学研究》,《中州学刊》2015年第3期。
[40]Franco Moretti, Distant Reading, 204.
[41]Franco Moretti, The Bourgeois: Between History and Literature,London: Verso, 2013, 14.
[42]相关文献参见苏劲松:《全宋词语料库建设及其风格与情感分析的计算方法研究》,厦门大学硕士学位论文,2007;王兆鹏:《建设中国文学数字化地图平台的构想》,《文学遗产》2012年第2期;郑永晓:《加快“数字化”向“数据化”转变——“大数据”、“云计算”理论与古典文学研究》,《文学遗产》2014年第6期;钱鹏、黄萱菁:《中国古诗统计建模与宏观分析》,《江西师范大学学报(自然科学版)》2015年第2期。
[43]如周琴:《安妮宝贝两部小说的语言学分析》,暨南大学硕士学位论文,2007年;曹莉敏、李海滨:《基于语料库的<金锁记>语言学分析》,《语文学刊》2010年第13期。
[44]邵燕君:《网络文学的“网络性”与“经典性”》,载邵燕君主编:《网络文学经典解读》,北京大学出版社2016年版,第7-9页。
[45]薛静:《都市言情:爱情已朽,如何重建神话?——以辛夷坞<致我们终将腐朽的青春>为例》,载邵燕君主编:《网络文学经典解读》,北京大学出版社2016年版,第241页。
[46]参见王恺文:《类型融合,求道求我》,载邵燕君、庄庸主编:《2015中国年度网络文学(男频卷)》,漓江出版社2016年版,第222-224页;肖映萱:《“大数据”时代的“反类型”》,载邵燕君、庄庸主编:《2015中国年度网络文学(女频卷)》,漓江出版社2016年版,第77-79页。
[47]陈海英:《文艺作品标题之语言学分析》,《天中学刊》2013年第5期。
[48]Franco Moretti, “Literature, Measured,” April 2016, p.7, https://litlab.stanford.edu/pamphlets/.
参考文献:
曹莉敏、李海滨:《基于语料库的<金锁记>语言学分析》,《语文学刊》2010年第13期。
陈海英:《文艺作品标题之语言学分析》,《天中学刊》2013年第5期。
陈静:《历史与争论——英美“数字人文”发展综述,《文化研究》2014年第2期。
陈晓辉:《大数据时代的文学研究方法——基于弗兰克·莫莱蒂文学定量分析法的考察》,《文艺理论研究》2016年第2期。
陈晓辉:《弗兰克·莫莱蒂的进化论马克思主义形式观》,《中国图书评论》2016年第3期。
陈晓辉:《弗兰克·莫莱蒂的三重文学空间观》,《西北大学学报》2016年第3期。
高树博:《小说对城市的想象》,《重庆广播电视大学学报》2014年第4期。
高树博:《论弗兰克·莫莱蒂进化论文学史观》,《绵阳师范学院学报》2014年第10期。
高树博:《弗兰克·莫莱蒂对“细读”的批判》,《学术论坛》2015年第4期。
胡咏梅、王建东:《基于Docuscope技术上非英语专业学生描写文写作研究》,《佳木斯教育学院学报》2010年第2期。
金雯、李绳:《大数据分析与文学研究》,《中国图书评论》2014年第4期。
梅新林:《论文学地图》,《中国社会科学》2015年第8期。
钱鹏、黄萱菁:《中国古诗统计建模与宏观分析》,《江西师范大学学报(自然科学版)》2015年第2期。
邵燕君:《网络文学的“网络性”与“经典性”》,载邵燕君主编:《网络文学经典解读》,北京大学出版社2016年版,第1-26页。
苏劲松:《全宋词语料库建设及其风格与情感分析的计算方法研究》,厦门大学硕士学位论文,2007。
王恺文:《类型融合,求道求我》,载邵燕君、庄庸主编:《2015中国年度网络文学(男频卷)》,漓江出版社2016年版。
王兆鹏:《建设中国文学数字化地图平台的构想》,《文学遗产》2012年第2期。
魏建亮:《关于“强制阐释”的七个疑惑》,《山东社会科学》2015年第12期。
吴雨平、方汉文:《“新文学进化论”与世界文学史观——评美国“重构派”莫莱蒂教授的学说》,《文艺理论研究》2013年第5期。
吴雨平、方汉文:《“文学世界体系”观念评骘》,《外国文学研究》2013年第5期。
肖映萱:《“大数据”时代的“反类型”》,载邵燕君、庄庸主编:《2015中国年度网络文学(女频卷)》,漓江出版社2016年版。
徐杰:《大数据时代的新媒体文学研究》,《中州学刊》2015年第3期。
薛静:《都市言情:爱情已朽,如何重建神话?——以辛夷坞<致我们终将腐朽的青春>为例》,载邵燕君主编《网络文学经典解读》,北京大学出版社2016年版。
张江:《强制阐释论》,《文学评论》2014年第6期。
张玉能:《本体阐释论质疑——与张江教授商榷》,《上海文化》2015年第12期,
郑永晓:《加快“数字化”向“数据化”转变——“大数据”、“云计算”理论与古典文学研究》,《文学遗产》2014年第6期。
周琴:《安妮宝贝两部小说的语言学分析》,暨南大学硕士学位论文,2007。
周志雄:《网络文学的发展与评判》,人民出版社2015年版。
[美]维克托•迈尔-舍恩伯格、肯尼思·库克耶:《大数据时代:生活、工作与思维的大变革》,盛杨燕、周涛译,浙江人民出版社2013年版。
Algee-Hewitt, Mark, Ryan Heuser, and Franco Moretti. “On Paragraphs. Scale, Themes, and Narrative Form.” October 2015, https://litlab.stanford.edu/pamphlets/.
Algee-Hewitt, Mark, Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, and Hannah Walser. “Canon/Archive. Large-scale Dynamics in the Literary Field.” January 2016, https://litlab.stanford.edu/pamphlets/.
Allison, Sarah, Ryan Heuser, Matthew Jockers, Franco Moretti, and Michael Witmore. “Quantitative Formalism: An Experiment.” January 15, 2011, https://litlab.stanford.edu/pamphlets/.
Allison, Sarah, Marissa Gemma, Ryan Heuser, Franco Moretti, Amir Tevel, and Irena Yamboliev. “Style at the Scale of the Sentence.” June 2013, https://litlab.stanford.edu/pamphlets/.
Dinsman, Melissa. “The Digital in the Humanities: An Interview with Franco Moretti.” Los Angeles Review of Books, March 2, 2016, https://lareviewofbooks.org/article/the-digital-in-the-humanities-an-interview-with-franco-moretti/.
Fish, Stanley. “The Digital Humanities and the Transcending of Mortality.” January 9, 2012, http://opinionator.blogs.nytimes.com/2012/01/09/the-digital-humanities-and-the-transcending-of-mortality/.
Kirschenbaum, Matthew G. “What Is Digital humanities and What’s It Doing in English Departments?” ADE Bulletin 150 (2010):1-7.
Moretti, Franco. Graphs, Maps, Trees: Abstract Models for a Literary History, London: Verso, 2005.
---. Distant Reading. London: Verso, 2013.
---. The Bourgeois: Between History and Literature. London: Verso, 2013.
---.“‘Operationalizing’: or, the Function of Measurement in Modern Literary Theory,” December 2013, https://litlab.stanford.edu/pamphlets/.
---. “Invisible objects,” https://www.wiko-berlin.de/en/fellows/alumni/fellows-club/newsletter/may-2014/franco- moretti-invisible-objects/.
---. “Literature, Measured.” April 2016, https://litlab.stanford.edu/pamphlets/.
Seal, Andrew. “We Have Never Been Well-Read: Franco Moretti's Pact with the Devil.” The Quarterly Conversation 33 (September 2, 2013), http://quarterlyconversation.com/we-have-never-been-well-read-franco-morettis-pact-with-the-devil.
Serlen, Rachel. “The Distant Future? Reading Franco Moretti.” Literature Compass 7.3 (2010): 214-25.
Shook, Karen. “The Author.” The Times Higher Education Supplement. June 27, 2013, https://www.timeshighereducation.com/books/the-bourgeois-between-history-and-literature-by-franco-moretti/2005020.article.
Wellmon, Chad. “Sacred Reading: From Augustine to the Digital Humanists.” The Hedgehog Review 17. 3 (Fall 2015), http://www.iasc-culture.org/THR/THR_article_2015_Fall_Wellmon.php.
主编 / 付梅溪 责编 / 顾佳蕙 美编 / 傅春妍


关注零壹Lab,获取更多数字人文信息!