Old-style Poetry Creation by Chinese Neo-literature Writers in the "First Decade" from the Perspective of Digital Humanities
Date: 2026-03-11
作者:王明俊 杨文佳 刘俊妍
一、引言
1917年2月,《新青年》发表胡适的八首白话诗,确立了中国新诗的起点,此后,在中国现代文学的“第一个十年”(1917-1927)期间,中国新诗不断发展并兴起。然而,当人们回顾这段文学史时,不仅发现了新文学家们对新诗写作的大力探索,同时也发现了大批新文学家在进行旧体诗创作。在五四“破旧立新”的文化语境下,这一现象极具文化考察的价值。如今学术界围绕这一话题已经产出一批研究成果,但多聚焦于个案考察、写作之因或诗学论争等领域,缺乏对于这一现象整体“大图景”式的考察和多维探勘。小组决定利用新兴的数字人文视角,采用文本探勘等技术,尝试推进新文学家旧体诗写作的整体研究,深入地开掘新文学家旧体诗写作的诗学特质。
二、研究方法与结果分析
(一) 数据采集与预处理

在数据来源上,从武汉大学李遇春教授主编的《中国现代作家旧体诗丛》以及新文学家的个人全集中,锁定了十五名代表性作家,分别选取他们在1917年至1927年所创作的旧体诗,其中有多首的合并作一首,除去标题,保留正文,共得到22000字,再去除停用词和标点符号(由于旧体诗创作较为凝练,字数较少,语义密度大,为了防止主题建模时语义丢失,后续研究未进行降维和筛选),采用南京农业大学团队基于《四库全书》语料训练的SikuBERT和sikufenci进行分词,最后归纳整理成excel,作为分析的基础语料。
(二)描述性分析
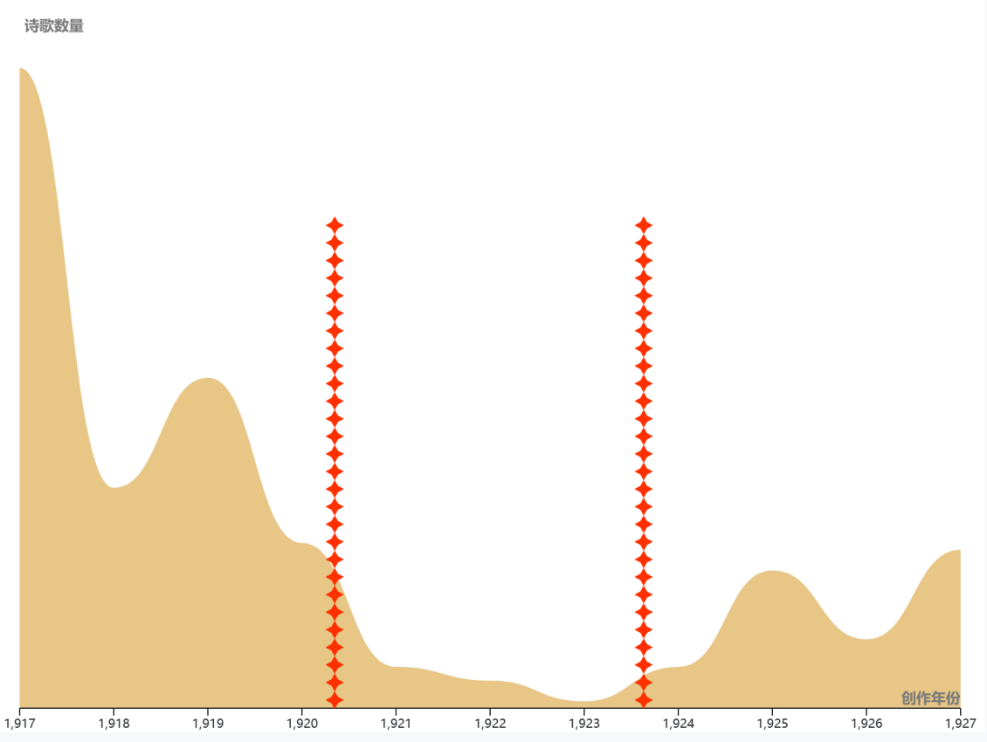
在收录进《中国现代作家旧体诗丛》丛书的十五位新文学作家中,第一个十年期间有旧体诗创作的共有九位,共计267首,其中郁达夫以140首旧诗创作的数量高居第一位,王统照与俞平伯分别以45首与32首居于第二与第三。
同时,根据采集到的数据结果,将1917-1927再细分为前中后三个时间段,以3年为一周期,即1917-1920,1921-1923,1924-1927,可以明显地看出旧体诗创作的整体的发展趋势:从新诗发生前期,亦即新旧交替时依旧保持一定的数量,再到新诗作为一种新的文学体裁逐渐稳定后,旧诗几乎不再被崇尚新文学的作家写作,最后到激烈的改革运动趋于末尾时,人们反思前期的激进,又开始重新拾起旧诗写作,并延续旧诗写作的传统。


俞平伯以一种相对稳定的态势在“第一个十年”期间很好地保持了旧体诗创作,这或许与他出身于传统文人世家有关(俞平伯为清代朴学大师俞樾曾孙);胡适、王统照、郁达夫等人明显受到五四运动影响,在1919年之后旧体诗创作数量剧减,其中由于1919年时郁达夫身在日本,相对于身在国内且为五四运动主将的胡适与王统照来说对国内文学改革的感知稍有迟钝,是于其1922年回国之后才开始大幅度减少创作;另外,有新文学家在1924年以后才开始进行旧体诗创作,如朱自清、鲁迅等,其中朱自清是由于在清华大学任教之后开始从事古典文学研究,创作了诸多拟古诗作,而鲁迅这一时期的作品,严格来说也只是套入某种旧体诗模版的白话打油诗写作,应该并没有有意地复古。
(一) 文本主题建模
潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)是一种对文本主题进行建模挖掘的三层贝叶斯产生式概率模型,该模型通过无监督学习,生成“文档-主题”和“主题-词”概率分布,被用于识别大规模文档集中潜藏的主题信息。LDA具有良好的数据降维能力和模型扩展性,被广泛应用于各种文本分析任务。此外也有基于LDA模型的改进与扩展模型分类相关研究,包括ATM作者主题模型与DTM动态主题模型。
1. ATM作者主题模型
ATM(Author-Topic Model)作者主题模型是是LDA主题模型的扩展。ATM模型能够分析语料库中作者的写作主题,找出作者的写作主题倾向,以及找到具有同样写作倾向的作者,可以用于揭示不同作者写作主题分布的差异。
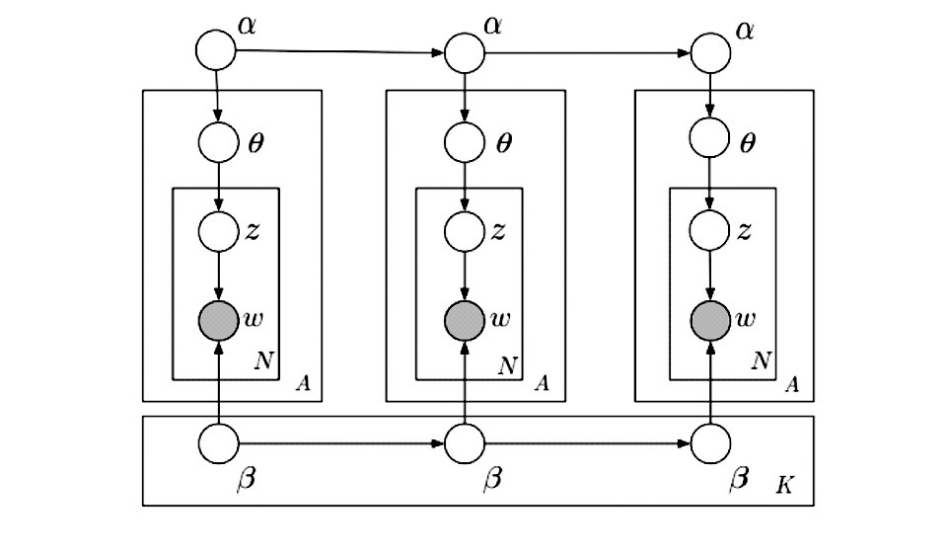
作者主题模型(Author Topic Model,简称ATM)是一种从大规模文本数据集中抽取文本主题信息的一种非监督机器学习算法。作者主题模型在经典主题模型的基础上将作者信息加入文本建模中,通过两阶段的随机过程对作者-主题分布以及主题-词分布进行抽样和参数估计,该模型的概率图模型如图所示。

该模型中文档集内词w和文档作者集合αd为可观测变量,可以从文档集内直接得到,在图上表示为有填充的圆,其他变量作者x、主题z、作者-主题概率分布θ、主题-词概率分布φ均为潜在变量,在主题模型中一般通过采用变分推断EM算法或Gibbs sampling方法进行估计,并以此得到作者-主题概率分布(K)和主题-词概率分布(T)。该模型的公式表示为:
P(词语|作者)=∑主题P(词语|主题)×P(主题|作者)
根据ATM模型主题一致性,从2-20的主题数,由于主题数量过多不易于展示和解读,因此此处选择13个主题来进行后续的研究。
1.1 主题词语分布
主题编号 | 主题标签 | 关键词列表 | 作者 |
Topic 1 | 江南忆旧 | 见、相、时、未、笑、数、君、千、江南、手、西、共、曰、清、重、心、更、入、忆、里 | 朱自清、俞平伯 |
Topic 2 | 月夜思乡 | 江、难、夜、相、长、问、今年、中、先、逢、旧、月、情、家、回、祝、更、定、怕、应 | 朱自清、郁达夫 |
Topic 3 | 江山夜醉 | 横、云、路、百、声、楼、醉、闻、梅花、夜半、江山、处、明朝、飞、堪、掌、咽、量、岸、拟 | 萧军、王统照 |
Topic 4 | 生死别离 | 妹、泪、难、中、死、未、心、汝、欲、生、成、忍、病、年、流、事、笑、吾、世、见 | 郭沫若、田汉、萧军 |
Topic 5 | 春风愁绪 | 吹、欲、寒、知、春、逢、千、朔风、愁、觉、开、桃花、郎、画、销、红、前、淡、懒、云 | 郭沫若、王统照、郁达夫 |
Topic 6 | 秋夜诗梦 | 怜、梦、作、诗、泪、秋风、忆、君、时、识、莫、初、中、泣、题、年、谈、空、昨夜、问 | 郁达夫、萧军 |
Topic 7 | 秋夜孤旅 | 独、客、一夜、云、知、梦、外、飞、闲、语、楼、霜、海、犹、更、秋、天、许、山、怜 | 王统照、胡适 |
Topic 8 | 家国情怀 | 爱、呼、头、鸣、摇、知、泪、翻、夫、头颅、光、安、清溪、血、屠、值、青、路、敌、百 | 鲁迅、胡适、朱自清 |
Topic 9 | 月夜怀人 | 月、相、年、时、诗、梦、花、未、想、中、思、天、生、书、君、开、须、老、雪、回 | 胡适、田汉、郁达夫、俞平伯、王统照、鲁迅 |
Topic 10 | 风尘天涯 | 云、愁、出、入、天涯、前、听、风、似、花、醒、冷、雨、倚、思、尘、双、苦、明、分 | 郭沫若、王统照、俞平伯 |
Topic 11 | 岁月流转 | 长、斜风、异、殊、岁、道、屡、哀、黄叶、侵、言、飙、啸、翠、笳声、君子、风、南、复、陌 | 朱自清、萧军 |
Topic 12 | 山水隐逸 | 流、更、怀、似、堪、渐、隐、乐、雨、酒、恨、齐、亲、登、山、带、歧、胡、家、暗 | 俞平伯、朱自清 |
Topic 13 | 未竟情思 | 未、成、意、欲、作、君、似、惊、感、知、愁、行、思、情、中、水、处、心、初、伤 | 郁达夫、王统照、朱自清 |
作者 | 主题 |
朱自清 | 江南忆旧、月夜思乡、家国情怀、岁月流转、山水隐逸 |
俞平伯 | 江南忆旧、风尘天涯、山水隐逸 |
郁达夫 | 月夜思乡、春风愁绪、秋夜诗梦、月夜怀人、未竟情思 |
萧军 | 江山夜醉、生死别离、春风愁绪、秋夜诗梦、岁月流转 |
王统照 | 江山夜醉、秋夜孤旅、风尘天涯、山水隐逸、未竟情思 |
郭沫若 | 生死别离、风尘天涯 |
田汉 | 生死别离、月夜怀人 |
鲁迅 | 家国情怀、月夜怀人 |
胡适 | 秋夜孤旅、月夜怀人、家国情怀 |
1.2 作者主题分布

作者主题偏好比例堆积图
1.3 作者主题偏好相似性

作者主题偏好相似性矩阵热力图
在新文学家旧体诗创作中,作者间的主题偏好相似性分析能够揭示文学流派的内在联系,反映作者风格的微妙差异,并映射出文学影响的复杂网络。通过量化作者对特定主题的选择倾向,深入地探讨文学流派的形成、作者风格的演变以及文学作品在社会文化背景下的反响和意义,从而在文学研究中实现对主题选择和创作动机更为精确的把握。其中作者主题偏好是根据作者主题概率分布的余弦相似度进行计算,其中主题偏好具有高相似度的作者对有:胡适-田汉、朱自清-俞平伯、郁达夫-王统照、郭沫若-田汉、王统照-俞平伯。
1. DTM动态主题模型
动态主题模型(Dynamic Topic Models,简称DTM)是一种用于文本数据分析的概率模型,主要用于发现文本数据背后的主题结构以及这些主题随时间的演化过程。
动态主题模型能够深入解析随时间流转文学作品中主题的演变轨迹,从而揭示不同主题在各个时期的创作数量和比例,反映文学焦点的迁移和流行主题的更迭。另外,该模型能细致地捕捉并展示单一主题在不同时间段的内涵变化,观察和理解文学创作如何响应并记录了社会文化演进和技术变革的脉络,更清晰地认识到新文学运动中旧体诗的创作是如何与时代精神相呼应,以及诗人是如何在维护传统的同时,对旧体诗进行创新和主题重构。
图中,w表示一个词;z是时间片段内文献文本集合d中词w的主题;θ服从带有参数α的狄利克雷分布(Dirichlet Distribution),决定文本集合的主题分布;β是狄利克雷先验参数(Dirichlet Prior),记录某个主题下生成某个单词的概率;词的数量N则是时间片段内的泊松分布决定;A表示时间片段内的文档数;K表示时间片段划分的数量。对于N中的每一个词,主题z由带有参数值θ的多项分布(multinomial distribution)选取,同时,词w是由基于z和β的多项分布选取。在t时刻,文献文本集的主题分布αt以及主题下词语分布βt,k均依赖于上一时刻的αt-1和βt-1,k,其依赖关系通过简易动态模型获取,见公式(1)和(2):
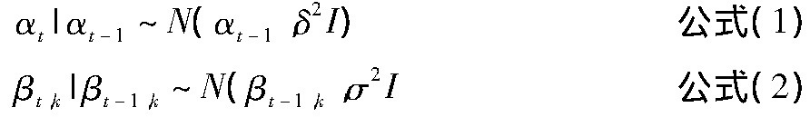
主题1 时过境迁 | 1917-1920 | 1921-1923 | 1924-1927 |
君、成、千、莫、声、年、意、中、思、知、欲、万、识、问、外、时、笑、惊、昨夜 | 千、郎、寄、万、问、成、天、年、君、外、时、笑、心、声、甘、冰、说、语、清 | 心、千、寄、问、莫、发、水、舟、翻、春风、愁、万、成、年、时、笑、甘、冰、说 | |
主题2 月夜情思 | 1917-1920 | 1921-1923 | 1924-1927 |
月、难、欲、影、重、意、夜、似、知、风、情、花、时、生、没、度、酒、水、忆 | 知、影、秋来、似、梦、月、难、花、漫、香、应、意、夜、故人、新人、情、若何、半、 | 故人、相、中、知、寒素、奢靡、行、花、年、影、秋来、似、梦、月、难、漫、香、应、夜 | |
主题3 梦回春晓 | 1917-1920 | 1921-1923 | 1924-1927 |
月、未、回、春、相、国、吾、花、天、空、作、似、诗、云、愁、意、梦、欲、情 | 未、回、春、相、似、云、梦、堪、事、时、月、怜、遍、独、秋、飞、真、国、吾 | 堪、前、春、回、未、相、似、梦、云、事、遍、怜、独、秋、飞、真、时、月、国 | |
主题4 风雨兼程 | 1917-1920 | 1921-1923 | 1924-1927 |
中、心、春、家、泣、怜、谈、月、惊、云、入、知、道、落叶、风雨、欲、似、愁、思 | 中、心、惊、梦、月、春、云、千、入、终、天、怜、举、泣、山、难、道、红、怀 | 忆、双、云、入、春、烟、难、举、尚、梦、红、处、十、怜、天、山、怀、笑、行 | |
主题5 春夜独吟 | 1917-1920 | 1921-1923 | 1924-1927 |
梦、中、云、欲、独、作、花、时、一夜、春、山、初、前、寻、处、冰弦、百、坐、真 | 欲、时、知、中、回、前、见、春、开、山、种、桃花、愁、闲庭、风雨、湖、许、梦、初 | 花、前、时、知、中、初、回、酒、见、春、开、山、种、桃花、闲庭、愁、风雨、湖、许 | |
主题6 战火纷飞 | 1917-1920 | 1921-1923 | 1924-1927 |
更、独、情、梦、思、亲、天涯、听、十、相、云、泪、月、文章、鸣、惊、处、惜、岂 | 爱、呼、独、鸣、头、情、处、夫、十、相、云、光、更、怨、外、惊、惜、血、头颅 | 呼、头、夫、鸣、光、头颅、血、青、独、处、怨、外、千、敌、里、克、服、阿呼、青剑 | |
主题7 旅人孤愁 | 1917-1920 | 1921-1923 | 1924-1927 |
意、难、行、人、怜、朔风、事、作、吹、未、秋、影、中、处、思、独、客、怨、万 | 影、中、处、愁、意、难、行、人、怜、朔风、事、作、吹、未、风、思、独、似、客 | 影、中、处、愁、意、难、行、人、怜、朔风、事、作、吹、未、雨、怨、客、思、独 | |
主题8 岁月似梦 | 1917-1920 | 1921-1923 | 1924-1927 |
妹、相、时、应、梦、日、未、学、远、中、长忆、江南、怜、尚、成、似、欲、吾、登 | 时、成、登、梦、生、未、妹、前、吾、难、明、愁、开、应、日、学、数、言、水 | 成、登、前、开、首、耶、风气、喜、收、时、梦、未、吾、难、明、愁、数、言、水 | |
主题9 生死沉思 | 1917-1920 | 1921-1923 | 1924-1927 |
难、年、天、江南、解、夜、死、成、空、日、泪、心、苦、中、诗、欲、山、云、相 | 未、解、知、死、空、国、处、生、欲、泪、身、云、年、江南、夜、山、见、伴、似 | 知、成、相、寻、见、翻、未、泪、法、共、想、头、赠、脸、理、高、生、云、燕 | |
主题10 风云变幻 | 1917-1920 | 1921-1923 | 1924-1927 |
欲、知、声、难、江、未、出、中、山、飞、云、风、行、明年、踏、丝、清、名、家 | 云、风、年、知、声、未、出、中、山、飞、难、江、双、行、踏、明年、丝、吃、便 | 风、双、欲、知、未、出、中、山、声、飞、年、难、江、行、初、时、生、踏、须 | |
主题11 书信传情 | 1917-1920 | 1921-1923 | 1924-1927 |
未、君、成、书、作、生、中、笑、相、愁、见、泪、感、情、日、行、断、处、独 | 作、欲、年、梦、君、成、重、相、日、非、知、逢、见、情、断、酒、卿、旧、笑 | 未、君、笑、作、情、见、新、思、聊、似、长、酒、非、重、言、成、前、入、敲 | |
主题12 孤寂思乡 | 1917-1920 | 1921-1923 | 1924-1927 |
独、未、愁、今朝、题、梦、相、窗、中、昨夜、君、思、意、水、家、笑、难、岁、读 | 君、怜、思、愁、今朝、意、家、水、心、难、千、笑、未、生、天、题、读、岁、入 | 君、心、千、见、思、生、天、入、更、歌、西、意、家、水、难、笑、草、行、闻 | |
主题13 | 1917-1920 | 1921-1923 | 1924-1927 |
思、相、梦、君、莫、知、识、问、开、春、门、今年、说、怜、行、心、怨、新年、少 | 未、相、门、开、梦、春、莫、花、知、中、时、今年、说、怜、行、君、出、似、天 | 惜、寻、思、花、见、门、开、春、中、出、似、天、天涯、未、相、莫、梦、今年、说 |
2.2 时间主题分布
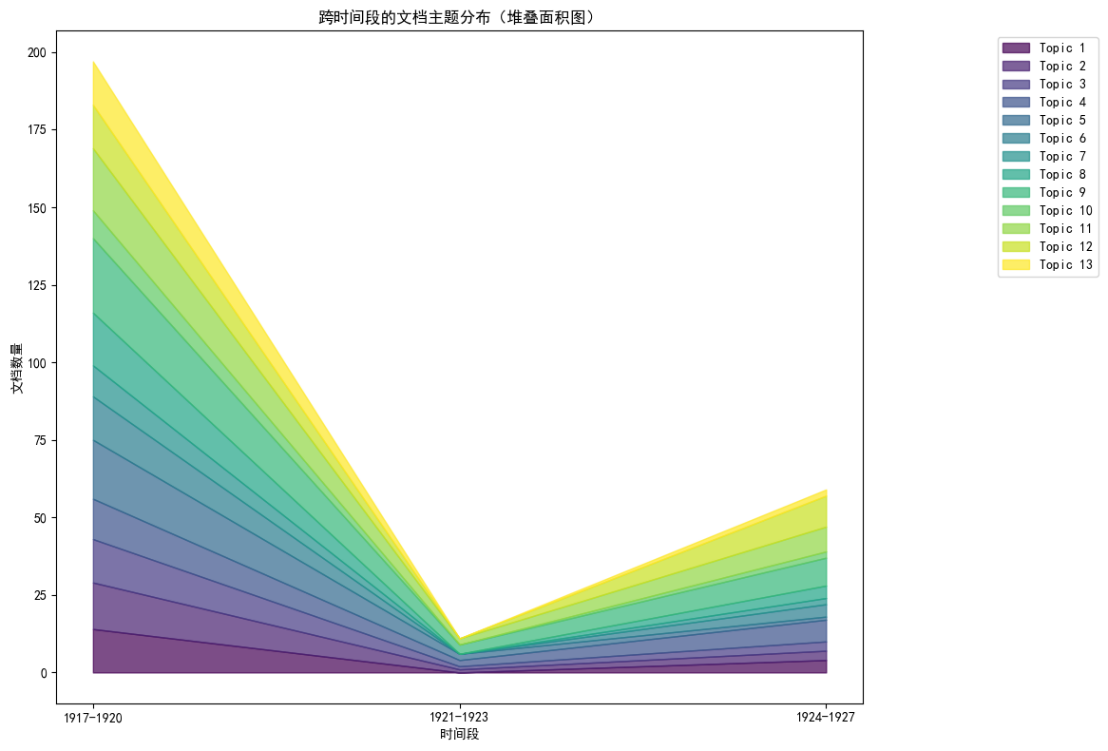
作品各主题数量随时间变化堆积面积图(侧重于绝对数量)
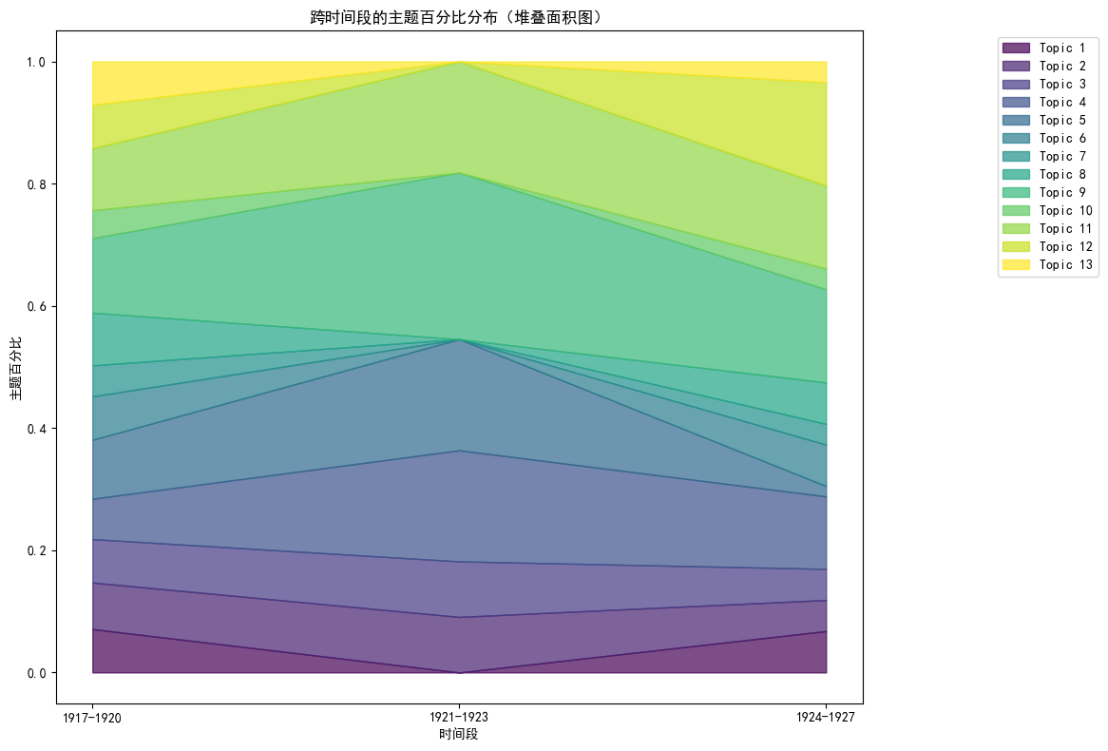
作品各主题数量占比随时间变化堆积面积图(侧重于占比)
由于中间时间段的文档数量较少,因此此处主要关注的是头尾两个时间段的主题分布,可以看到主题5的占比显著减少,主题12的占比增多,其余部分主题占比较为稳定。(四) 语义密度计算
从旧体诗到白话文的语义密度变迁可以衡量文学发展和语言演变,反映新文学家的复古或革新的思想倾向。Maton (2014: A-37) 用语义密度来指社会文化实践中意义的浓缩程度。语义在实践中的浓缩程度越高,语义密度越强;
语义密度通过三个手段观察:措辞中的语义密度、小句中的语义浓缩和序列中的语义浓缩。其中措辞中的语义密度指整个语篇中的语义密度,可以通过包含较高语义密度的术语、抽象名词和名词化的整体分布来观察。小句中的语义浓缩指小句中包含较高语义密度词语多少。序列指小句复合体中所包含的具有较高密度值词语的分布。增强语义密度的方式包括:
(1)将一连串的意义压缩为专业术语;
(2)将过程意义浓缩为抽象名词或名词化。语义密度主要由专业术语和名词化来体现。专业术语的语义密度高,一方面与其本身体现的专业性和抽象性有关,同时也与该学科话题范围有关(Martin 2013;吴奇格、朱永生2016)。
语篇的语义密度体现为术语和名词化表达的出现频次。语义密度测量可以参考Ure(1971)的实词密度计算公式。Ure的公式通过计算实词与总词数的百分比获得。语义密度的计算可以通过专业术语和名词化与语篇总词数的百分比获得。测量公式如下:

在文学作品的语境下,此处把语义密拆分为意象表达,情感表达,与名词化表达,即:

经过上述语义密度的计算,各诗人作品的平均语义密度如下所示。作为对照,选取了部分唐代诗人的作品计算平均语义密度,结果为26.37%。(包括杜甫、李白、白居易、元稹、李商隐、孟郊、温庭筠、王维九人,数据来自Github)

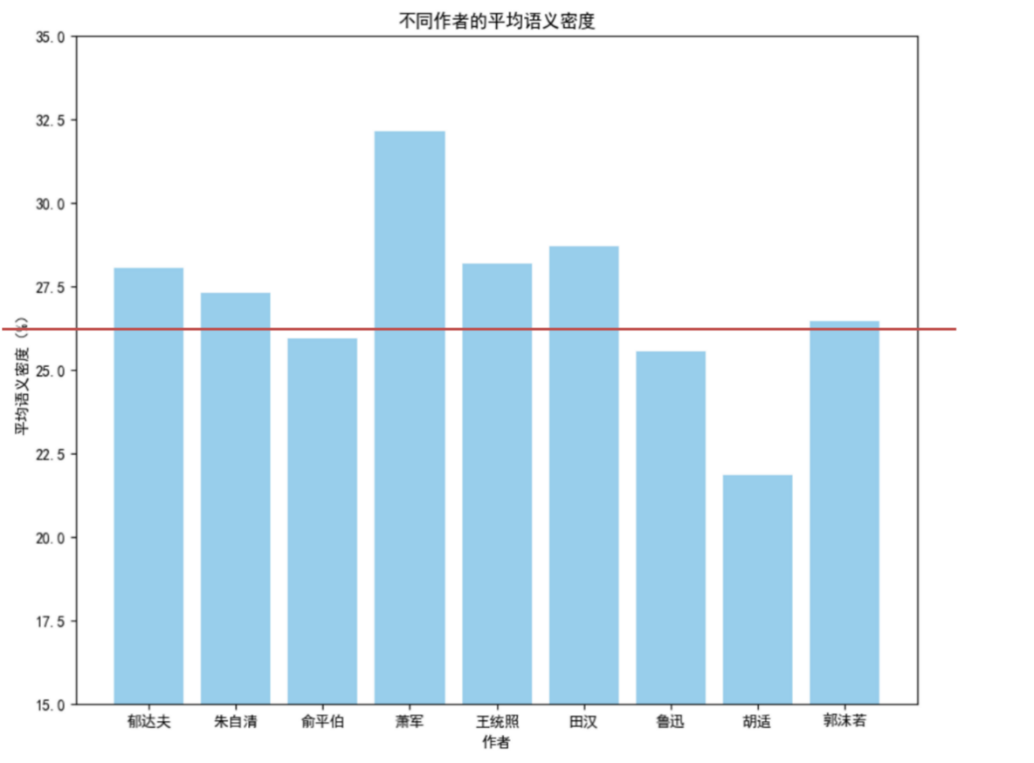


回到各诗人的旧体诗创作作品中,可以观察到作为新文学家代表中的鲁迅和胡适创作的旧体诗中的用词已经有明显的现代化特征,而萧军和田汉在旧体诗创作中仍然遵循旧体诗创作的严谨的规则。
(五) 词频统计
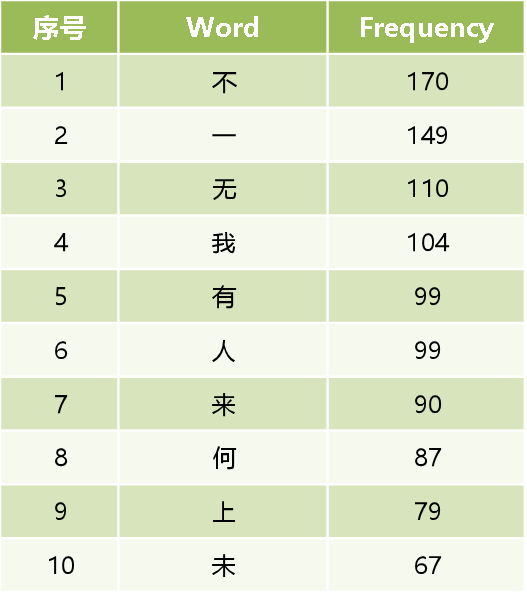
在收集的语料库中,对词语进行词频统计与分析,发现在词频前十的词语中,出现了多个否定性词,如第一位的“不”,第三位的“无”,第十位的“未”,共计有347次。这可以表现这一时期新文学家旧体诗创作中的否定性倾向。这种“否定性”的出现不是偶然,而是与他们的新文化思想及此时的社会现实有关。
在词频统计的前十位中,“我”出现了104次,居第四位,小组继续对人称代词进行搜索,发现如下结果:“吾”出现了17次,“你”只出现了7次,“汝”出现了9次,“他”出现了28次,“她”出现了6次。总的来说,我们发现在这一时期的旧体诗创作中,第一人称的使用居于主位,这种现象应与五四时期个人主体性的解放及“人的精神”有关,同时前十位中“人”出现了99次,也能说明这一问题。
五、不足与改进
首先,从现在收集到的文本及分析结果来看,中国现当代文学“第一个十年”期间新文学家的旧体诗创作并不像部分论文所展现地如此“繁荣”,与新诗相较,仍然呈现出一种衰落和式微的态势,只不过在这样的态势内部亦有“高-低-高”的结构存在,只有郁达夫等少数人是专注于旧诗写作而不学新诗的,同时,这一时期的文本量远未达到小组预期,或许在之后需要继续填补语料,或采用延长时段的方法来保证数字人文方法在本研究中使用的合理性和必要性。
其次,由于数据收集与时间的限制,目前缺乏同一时期现代诗在数据上的对照组,或言同一时期现代诗的“史料”,现代性的角度更多的是从现代理论和现代思想出发,并不是文本与文本进行对话,而是理念与文本进行对话。
在后续的研究中,首先需要重新审视新文学家的选取范围的界定,引入这类新文学家的新诗作为对照,以此补充目前主题分析上可解释性的不足。在各个新文学家的创作历程上,也需要整理相关的创作数量的数据作为整体观察。