An Analysis of the "Niao·Huan" Relationship in Legend of Zhen Huan from the Perspective of Digital Humanities
Date: 2026-03-11
作者:张美姗 钱柯羽 向鋆欣 程铄雯
1. 引言
《甄嬛传》是由郑晓龙执导的大型古装宫斗类电视剧,改编自流潋紫的网络小说《后宫·甄嬛传》,2011年开播至今,一直保持着很高的收视率、网络点击量和社交平台讨论热度。
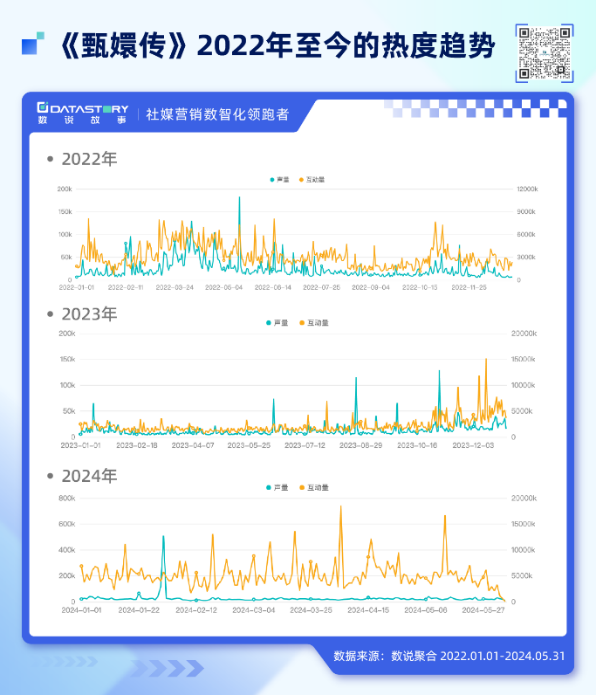
图 一 根据数说故事旗下数说聚合数据,2022年至今,甄嬛传在主流社媒平台(微博、微信、小红书、抖音、Bilibli等)上的声量超1700万+,互动量超27亿+。亿万网友一次又一次的互动,不断增加着“甄嬛宇宙”的纵深。
该剧以清朝宫廷为背景,通过复杂的人物关系和跌宕起伏的情节,讲述了一个不谙世事的单纯少女成长为一个善于谋权的深宫妇人的故事。“鸟嬛”关系作为剧中的一条重要线索,在2024年初,再次引发了观众的广泛讨论和思考,由剧中衍生出的“鸟嬛文学”在社交媒体平台上热度不减,直到年底仍然有二创作品获得较高点击量。鸟嬛”关系指的是角色甄嬛与安陵容(观众称安陵容为“安小鸟”)之间的复杂关系,剧中,安陵容与甄嬛从年少初遇的好友走向相互戕害的对立阵营,这看上去好像只是一个简单的“阴暗女配”支线故事。从一个“善妒反派”的形象走向“因爱生恨的悲剧女性”,观众对安陵容的认知与评判随着剧集播出至今也发生了微妙的变化。
在有关“鸟嬛”关系的讨论当中,安陵容究竟是嫉恨甄嬛荣宠、渴望得到皇恩的反派宫妃还是因无法在甄嬛身上得到自我确立而走向对立的昔日旧友?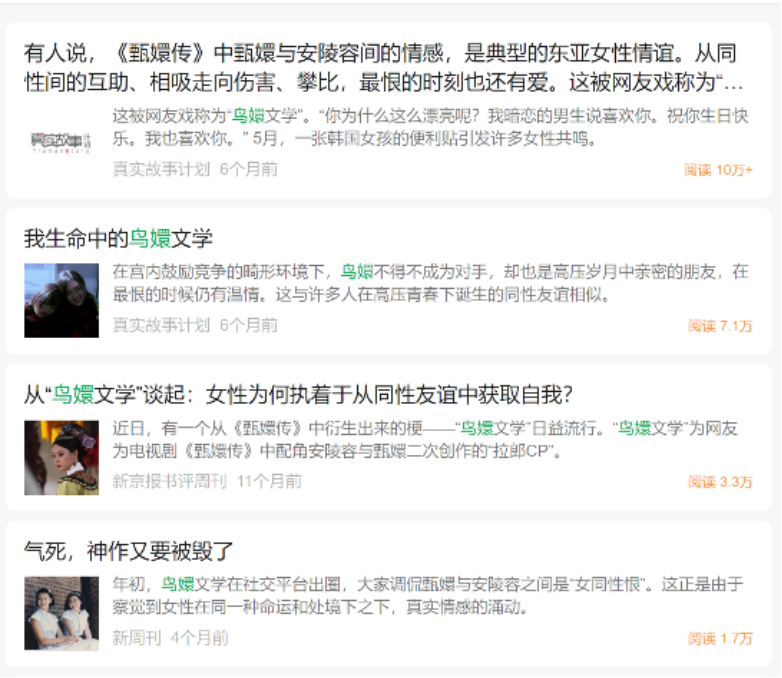
图 二 微信公众号平台中与“鸟嬛”关系有关的文章阅读量暴涨

本项目旨在运用数字人文的方法,希望通过多角度的文本探勘,对《甄嬛传》剧本中的“鸟嬛”关系、情感、权力变化进行深入解析,探讨在特定的社会结构和文化背景下,女性如何通过彼此的关系来寻求认同、支持和生存策略,揭示女性在权力结构中的处境,她们如何在限制和挑战中寻找自我价值和力量、如何在复杂的社会关系网中谋求自身利益和发展。
除了从艺术作品创作角度深化对《甄嬛传》女性形象关系的理解,本项目也为数字人文在剧本分析中的应用提供了新的案例;此外,本项目也将致力于讨论数字人文方法在分析复杂人物关系中的有效性和局限性,试图探讨影视剧文本勘探未来研究的方向,包括方法的改进和应用的扩展。
2. 《甄嬛传》剧本数据来源与数据清洗
由于目前并无官方剧本公开出版,本文将以道客巴巴平台上网友编撰、订校并上传的《甄嬛传》剧本电子版为原始数据来源,经过与剧目对比,该文本情节还原、信息丰富、错误较少,且具有结构化特征,具备良好的文本挖掘基础。
我们利用Python、Gephi等工具,通过数据采集、数据清洗、数据处理、数据可视化、数据分析等流程对《甄嬛传》剧本中安陵容、甄嬛二人的关系进行全面而系统的研究,实现对剧本人物关系的挖掘和发现。
其中,数据采集阶段主要是对剧本的文本进行爬取,并以txt文件的形式保存爬取出来的数据。数据清洗阶段是利用Python中的jieba库进行分词,提取剧本中的人物、台词等内容,并进行数据结构化处理。数据处理阶段是运用python对剧本中的人物角色关系、词频分布与主题、情感倾向等方向进行分析。数据可视化阶段是运用Gephi软件或者python可视化库对数据进行可视化呈现,形成可视化图谱。数据分析阶段主要是对可视化图谱内容展开分析发掘,实现文本内容与数字技术的结合。
3. 社会网络与人物共现关系中的安陵容与甄嬛
3.1. 提取人物共现关系实验细节:
首先是加载自定义字典与自定义停用词、人物映射表:定义了一个字典name_mapping,其中键是标准的人物名字,值是该人物在剧本中可能出现的所有别名。对每一行文本进行分词,并过滤掉停用词。对于每个词,如果其词性是nr(表示名词,通常是人名),且长度大于等于2,则认为是一个有效的名字。根据alias_mapping将名字标准化,并记录每个名字的出现次数。
其次是构建人物共现关系:在同一行内出现的名字被视为共现关系,采用两种不同的形式赋权,第一种是对话共现,即人物在同一幕中存在对话关系;第二种是台词共现,即人物并不一定真实共现但在台词中出现。第一种权重较高,第二种权重较低。以此统计共现关系,并过滤掉共现次数较少的关系(设置值为4)。

图 四 代码实现的部分细节
3.2. 运用Gephi可视化
将所得到人物与共现关系数据绘制到Excel表格,以CSV格式保存,利用Gephi软件读取表格数据,并进行人物矩阵网络关系图绘制。在操作过程中设置节点的大小,节点大小与度相关,度越大则节点面积越大。此外,连接两节点的边的粗细程度反映了两节点联系的紧密程度,两节点间的边越粗则代表联系越紧密,可视化结果如图五所示。
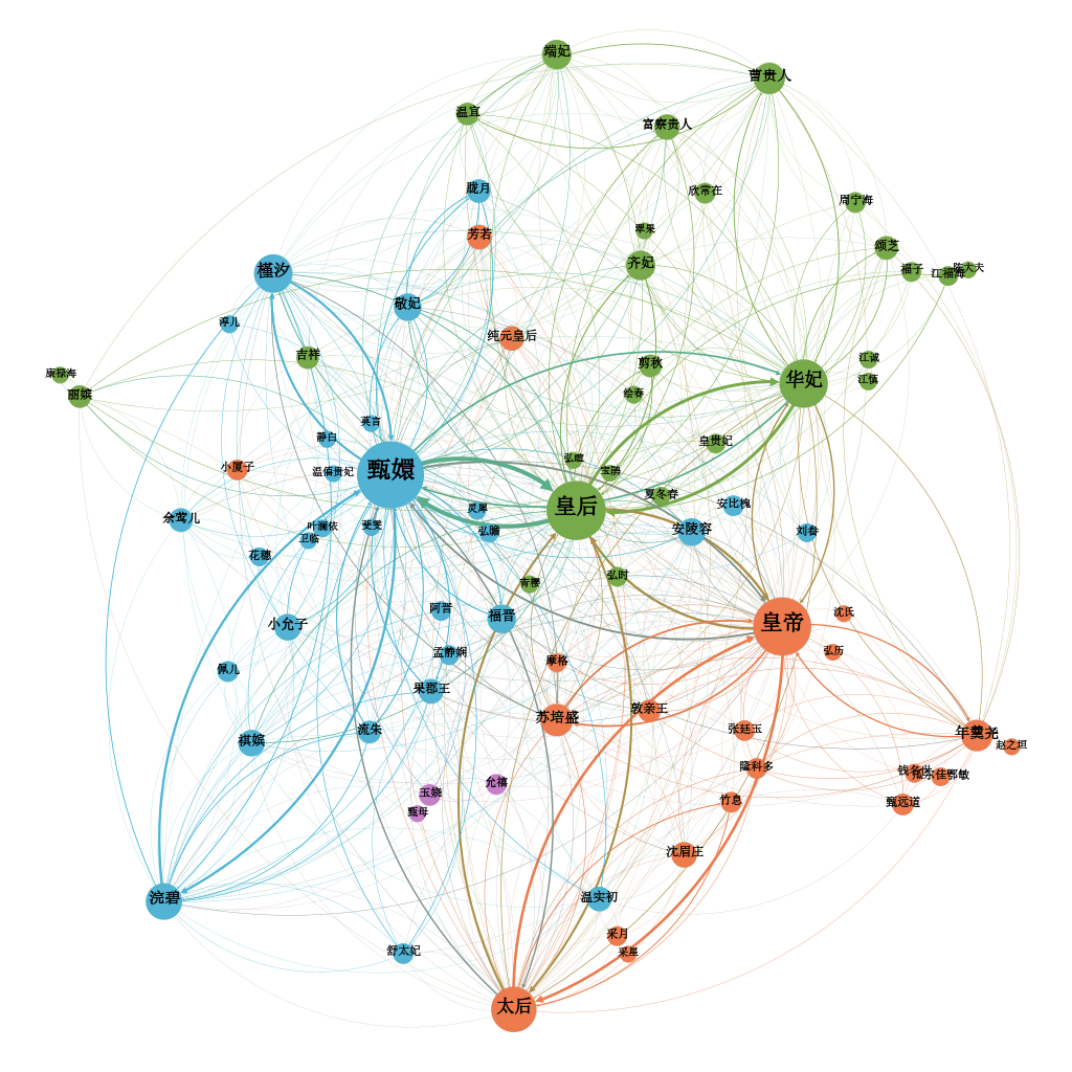
图 五 《甄嬛传》全剧本人物网络关系图
3.3. 人物共现关系的网络特征指标分析
选取标准的解析度1.0进行统计,得出表一人物共现关系的网络特征指标,网络特征指标分析人物共现关系网络的拓扑结构可以通过网络平均度、平均路径长度、平均聚类系数等指标进行分析,《甄嬛传》人物共现关系的网络特征指标数据如表一所示。
数据集 | 节点数 | 边数 | 网络直径 | 网络平均度 | 平均聚类系数 | 平均路径长度 |
人物关系网络 | 80 | 644 | 5 | 8.05 | 0.563 | 2.231 |
表 一 《甄嬛传》人物共现关系的网络特征指标
通过表一可以看出,本次录入的角色人物共80位,他们相互之间构成的社交关系共644条。共现关系网络中的人物,平均需要2—3步即可建立联系,而最长则需要5步才能建立。网络中的每个人物平均与8—9个其他人物存在共现关系。每个人物之间的平均聚类系数为0.563,即共现概率为56.30%。综上所述,《甄嬛传》中的人物联系较为紧密,具有较为明显的小世界特性。
3.4. 基于“安陵容——甄嬛”的人物网络关系分析
在Gephi中进行统计,并导出节点统计数据,分别保存为模块化、离心率、接近中心性、谐波接近中心性、介度中心性、聚类指标。由图可知,安陵容权重并不高,接近中心性、谐波中心性指数排名分别为16/80和15/80,没有呈现出明显的“中心性”。
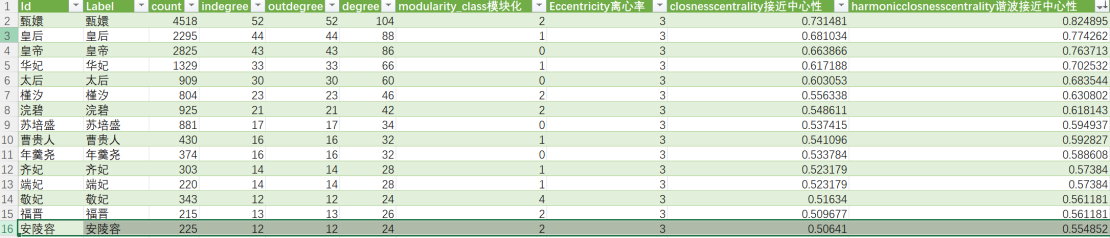
图 六 “安陵容”节点的谐波中心性指数排名
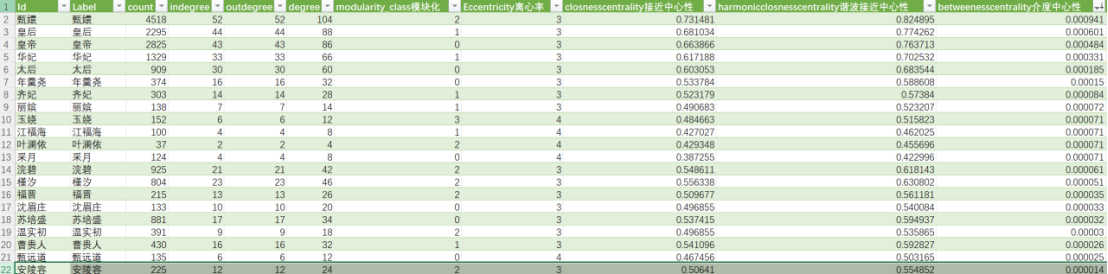
图 七 “安陵容”节点的介度中心性指数排名
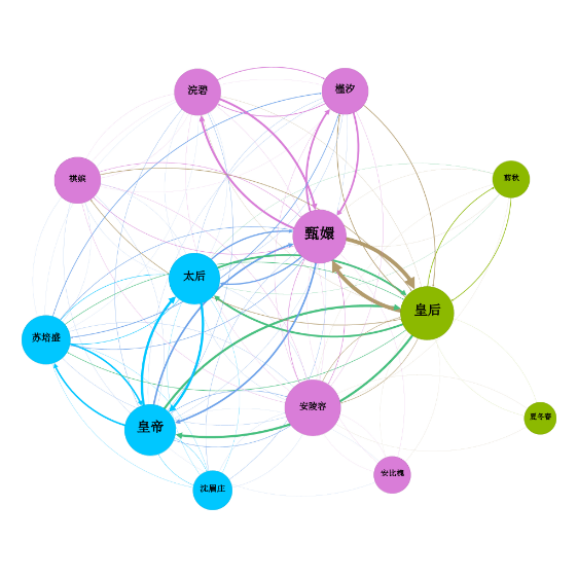
根据《甄嬛传》人物在共现关系网络中的中心度排名、基于模块化的凝聚子群分解,用Gephi模块化功能对《甄嬛传》中的不同群体进行着色,以图谱的形式呈现人物的共现关系网络,从而较为清晰地区分互动相对频繁的群体,结果如图所示。主要分为三个群体,核心人物分别为甄嬛、皇后、皇帝。

图 八 《甄嬛传》人物模块化分解共现网络
在Gephi中使用滤波,用两个ego network过滤器并用union联合器将其逻辑统一,排除与甄嬛、安陵容两个节点无关的或者相对弱的节点,可以发现一个聚类与布局的冲突:在Force Atlas 2布局中,安陵容在聚类上属于“甄嬛”中心圈,但布局有远离甄嬛中心圈的趋势,与传统的认为安陵容属于皇后阵营的观点有所不同。
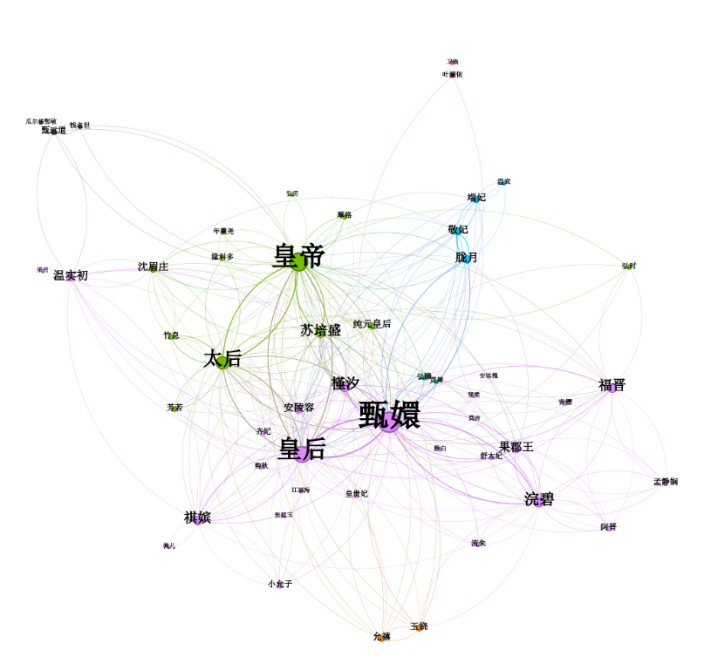
考虑到安陵容角色的前后变化,特选取剧情中甄嬛与安陵容决裂的集数第44集作为分割,重复提取人物关系数据与可视化的操作,形成图十“第44集前人物共现关系图”与图十一“第44集后人物共现关系图”,实验结果发现,二人关系无论对立与否,安陵容在模块化聚类分析中仍然属于“甄嬛”核心圈,但紧密度有所下降,在图十一中介入皇后、皇帝、与甄嬛三角之中。不仅体现出远离甄嬛核心圈的趋势,更表现出安陵容介入其他角色复杂度的上升。
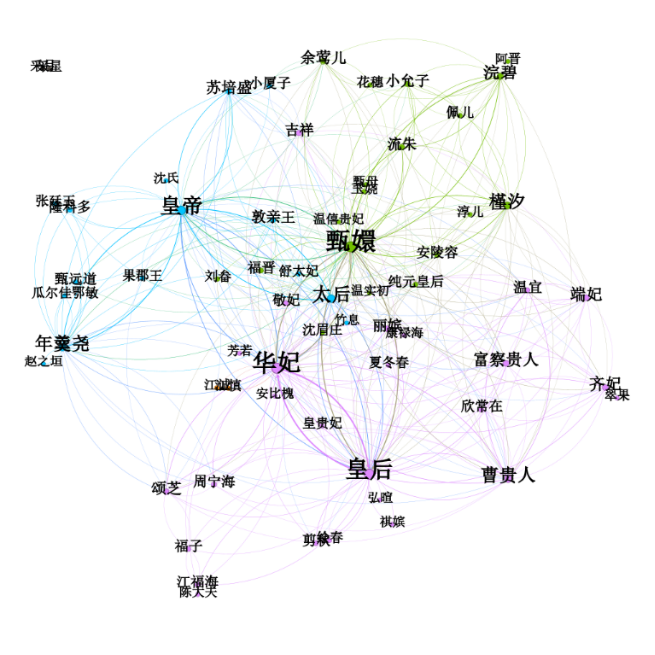
图 十 第44集前人物共现关系图
4. 基于剧本台词的词频统计与词汇分析
4.1. 词频统计与分析
我们截取了安陵容的戏份中甄嬛和安陵容的台词做了比照,并以词云图展现。

图 十二 安陵容台词词频图(左)和甄嬛台词词频图(右)
4.2.基于LDA模型的台词词汇主题分析

图 十三 4.2. 基于LDA模型的台词词汇主题分析的部分技术细节
1 | 0.009*"喜欢" | 0.005*"孩子" | 0.005*"宫中" | 0.004*"东西" | 0.003*"多谢" | 0.003*"身子" | 0.003*"话" | 0.003*"麝香" | 0.003*"回去" | 0.003*"贵人" |
2 | 0.006*"死" | 0.005*"宫中" | 0.004*"嫔妾" | 0.004*"贵妃" | 0.004*"喜欢" | 0.003*"从前" | 0.003*"孩子" | 0.003*"担心" | 0.003*"不该" | 0.003*"明白" |
3 | 0.005*"姐妹" | 0.005*"喜欢" | 0.004*"蓬莱" | 0.004*"洲" | 0.004*"绣" | 0.004*"香囊" | 0.004*"宫中" | 0.002*"请安" | 0.002*"真的" | 0.002*"宠爱" |
4 | 0.006*"太医" | 0.006*"东西" | 0.006*"父亲" | 0.004*"香" | 0.004*"身子" | 0.004*"甘露寺" | 0.004*"不知" | 0.003*"贵人" | 0.003*"孩子" | 0.003*"宫里" |
5 | 0.005*"公主" | 0.004*"宫中" | 0.004*"张公公" | 0.004*"孩子" | 0.004*"诅咒" | 0.003*"姐妹" | 0.003*"揣测" | 0.003*"后宫" | 0.003*"不要紧" | 0.003*"糊涂" |
表 二 安陵容台词主题分析
1 | 0.006*"喜欢" | 0.005*"宫中" | 0.005*"麝香" | 0.004*"香料" | 0.004*"太医" | 0.003*"不知" | 0.003*"死" | 0.003*"孩子" | 0.003*"身子" | 0.003*"药" |
2 | 0.005*"喜欢" | 0.004*"孩子" | 0.004*"陪" | 0.004*"公主" | 0.004*"宫中" | 0.003*"姐妹" | 0.003*"回去" | 0.003*"多谢" | 0.003*"里" | 0.002*"郡王" |
3 | 0.007*"东西" | 0.006*"太医" | 0.006*"父亲" | 0.005*"喜欢" | 0.004*"走" | 0.004*"事情" | 0.003*"身子" | 0.003*"贵人" | 0.003*"郡王" | 0.003*"姐妹" |
4 | 0.004*"贵人" | 0.004*"甘露寺" | 0.004*"东西" | 0.004*"担心" | 0.003*"洲" | 0.003*"蓬莱" | 0.003*"此事" | 0.003*"揣测" | 0.003*"锦" | 0.003*"公主" |
5 | 0.005*"东西" | 0.005*"宫中" | 0.004*"孩子" | 0.004*"后宫" | 0.004*"从前" | 0.004*"身子" | 0.004*"喜欢" | 0.003*"宫里" | 0.003*"入宫" | 0.003*"不好" |
表 三 安陵容与甄嬛二人台词主题分析
1 | 0.009*"东西" | 0.005*"宫中" | 0.004*"姐妹" | 0.004*"明白" | 0.003*"喜欢" | 0.003*"回去" | 0.003*"生气" | 0.003*"舒痕" | 0.003*"胶" | 0.003*"孩子" |
2 | 0.005*"后宫" | 0.004*"宫中" | 0.004*"贵人" | 0.003*"姐妹" | 0.003*"入宫" | 0.003*"郡王" | 0.003*"喜欢" | 0.003*"得宠" | 0.003*"宫里" | 0.003*"永寿" |
3 | 0.006*"郡王" | 0.005*"果" | 0.005*"贵人" | 0.003*"伺候" | 0.003*"宫中" | 0.002*"陪" | 0.002*"菊青" | 0.002*"贵妃" | 0.002*"女子" | 0.002*"不要紧" |
4 | 0.007*"太医" | 0.005*"孩子" | 0.004*"身子" | 0.004*"父亲" | 0.004*"东西" | 0.004*"身孕" | 0.003*"喜欢" | 0.003*"事情" | 0.003*"月" | 0.003*"麝香" |
5 | 0.006*"喜欢" | 0.005*"身子" | 0.003*"话" | 0.003*"走" | 0.003*"请安" | 0.002*"心意" | 0.002*"真" | 0.002*"放心" | 0.002*"甄母" | 0.002*"不适" |
表 四 甄嬛台词主题分析
4.4. 结果分析
4.4.1. 高频词分析
在统计中,“姐姐”(513次)、“妹妹”(60次)等称呼频繁出现,体现了两人初期亲近的关系。这些词语多出现在剧情的早期阶段,表现出安陵容对甄嬛的依赖与仰慕。然而,随着故事推进,“多谢”(32次)、“怨恨”(10次)等词语的出现,显示两人情感的裂痕。4.4.2. 情绪化词汇
安陵容的词频中,“伤心”(11次)、“心寒”(2次)、“怨恨”(10次)等词语较为显著,表现出她由怯弱到心生怨愤的心理转变。这与甄嬛词汇中的“宽慰”(1次)、“劝劝”(1次)等安抚性表达形成鲜明对比,显示甄嬛对安陵容态度上的隐忍与克制。
4.4.3. 主题词汇对比
甄嬛:甄嬛的词频中出现较多诸如“孩子”(30次)、“自己”(28次)、“太医”(28次)等词,表现出她在宫廷生活中的权力意识及关注。
安陵容:安陵容词频中与身份和情感相关的词汇较多,如“贵人”(42次)、“嗓子”(13次),表现出她对恩宠的追求和自卑心理。
5. 基于剧本台词的情感分析
5.1. 技术细节:
5.1.1. 读取多个 .docx 文件
首先,我们需要读取多个剧本台词(.docx)文件并合并它们的内容。使用 python-docx 库可以非常方便地读取 .docx 文件中的每个段落。读取文件:使用 Document 类读取 .docx 文件,并通过 .paragraphs 获取所有段落文本。
5.1.2. 文本清洗和处理
处理文本中的一些特殊字符,比如去掉括号中的内容,场景布局等。接着,我们需要根据剧本的场景来分割文本。通过正则表达式匹配“第n幕”或“第x集”等标记,然后将其分割成不同的场景。
5.1.3. 角色和台词提取
然后,我们从每个场景中提取出角色和台词。通过正则表达式匹配 "角色名: 台词" 的格式,提取出角色名和相应的台词。接下来,我们进行过滤:只保留包含“甄嬛”和“安陵容”台词的对话,或者是它们之间相邻的台词。
5.1.4. 情感分析
使用 SnowNLP 进行情感分析,评估每个场景的情感倾向,并将情感得分保存下来。情感得分的范围是 0 到 1,其中接近 1 表示正面情感,接近 0 表示负面情感。
5.1.5. 绘制折线图
最后使用matplotlib来绘制情感得分的折线图,生成图片并保存。
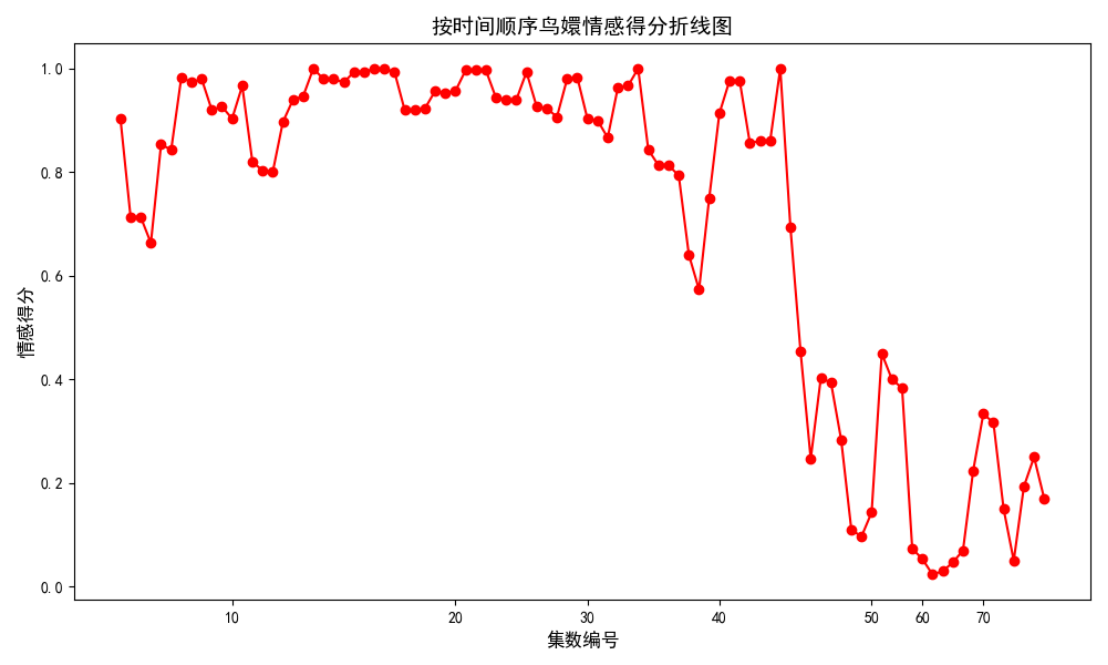
5.2. 节点说明
安陵容“下线后”的数据:例如第70集甄嬛回忆“皇后杀了皇后”
首次出现“负面”:蓬莱洲集,安陵容被皇后派去监视甄嬛;此时安陵容早已加入皇后战队,但未与甄嬛明面上交恶。
关键节点:
选秀相遇(第1幕):甄嬛帮助安陵容解围,安陵容表示感激,奠定了两人初期友好的基础,关系情感得分1.00,为后续的交往拉开序幕。
入宫初期(第2幕-第20幕左右):安陵容在宫中受到欺凌,甄嬛和沈眉庄时常安慰她,三人相互扶持,关系进一步升温。如安陵容为甄嬛打抱不平,毒杀余莺儿,甄嬛也在生活中关心安陵容,赠送礼物等,此阶段得分多在0.90 1.00之间。
父亲获罪事件(第273幕-第313幕):安陵容父亲下狱,甄嬛积极为其求情,两人关系看似更加紧密。甄嬛不仅安慰安陵容,还带她向皇后求情,最终安陵容父亲无罪释放,安陵容因此得宠。这段时间关系情感得分维持在较高水平(0.94 1.00),但也成为关系变化的一个潜在转折点,安陵容心态开始发生变化。
舒痕胶事件(第489幕-第559幕):安陵容送甄嬛舒痕胶,后被发现其中含有麝香,导致甄嬛小产。这一事件是两人关系的重要转折点,甄嬛开始对安陵容产生怀疑,关系逐渐疏远,得分下降至0.53 0.99之间,负面因素开始增加。
彻底决裂(第564幕-第1169幕):随着剧情发展,安陵容与甄嬛之间的矛盾不断激化,如在皇上面前争宠、互相猜忌等。在第659幕中,安陵容为让甄嬛喝人血入药的药,两人发生激烈争吵,关系彻底破裂,此后得分多在0.00 0.38之间,充满了怨恨和敌意。直到最后安陵容临死前,与甄嬛的对话仍充满仇恨,表明两人的关系已无法挽回。
5.3. 关系情感得分变化趋势
整体趋势:呈现先上升后下降的趋势,从最初的正面逐渐走向负面。
具体阶段:
初期(第1幕 第214幕左右):关系情感得分较高,多在0.71 1.00之间,表明两人关系处于友好、互助的状态,如安陵容多次表达对甄嬛的感激,甄嬛也积极帮助安陵容,为其父亲求情等。
转折期(第225幕 第559幕左右):得分开始出现波动,有部分中性和稍显负面的评价。这期间安陵容虽仍有与甄嬛看似友好的互动,但一些行为已开始引起甄嬛的疑虑,如送甄嬛舒痕胶,甄嬛发现其中有麝香后,关系开始出现裂痕。
恶化期(第564幕 第1169幕):得分大幅下降,多在0.00 0.50之间,且负面评价居多。此时两人关系彻底破裂,安陵容多次与甄嬛发生冲突,言语间充满敌意,甄嬛也认清了安陵容的真面目,对其充满怨恨。
通过对数据变化和关键节点的分析,可以清晰地看到安陵容和甄嬛关系的演变过程,从最初的姐妹情深到逐渐疏远、破裂,最终反目成仇,这一过程反映了后宫复杂的人际关系和人性的多面性。
6. 结论与反思
本文结合数字人文视角,利用词汇主题分析、社会网络分析和情感分析等技术,揭示了甄嬛与安陵容复杂多变的关系演化轨迹。研究发现,两人关系经历了从初期的亲密互助到逐渐疏远,最终决裂的过程,表现出后宫权力博弈中情感与利益交织的张力。通过词频统计与LDA主题分析,本文还探索了角色台词中隐含的情感与权力动态,突出其叙事中的深层逻辑。此外,利用 Gephi 绘制的人物关系网络清晰呈现了剧中角色互动的模块化特征,尤其是安陵容在不同阶段的关系重心变化。研究不仅深化了对该剧复杂人物关系的理解,也为数字人文方法在影视剧分析中的应用提供了实践参考。
通过各种分析方法,我们突破了传统影视解读的局限,使角色之间的情感冲突和权力关系的动态变化得以可视化呈现,为观众提供了更直观的理解路径,也进一步验证了数字人文技术在影视剧本分析中的潜力和适用性。本研究为数字人文在剧本分析中的应用提供了新的案例。其主要价值在于以下两方面:
社会网络分析:揭示剧中人物关系的结构和权重分布,使角色互动模式更为清晰。
主题模型分析:分析角色台词主题,捕捉情感冲突与权力动因的潜在逻辑。
这些技术手段的融合,不仅拓展了剧本分析的可能性,也为其他剧本或文学文本提供了研究方向的借鉴。
然而,尽管本研究取得了一定成果,但在多个环节仍存在可改进之处,未来研究可以从以下几个方向深化与拓展:
首先,研究目标的进一步细化与优化。当前的关系解析尚显笼统,未来可以围绕特定主题(如权力、情感、伦理等)开展更细化的分析,挖掘角色关系的多层次意义。
其次,从量化到质化的平衡。除了揭示角色关系的“复杂性”,还需要进一步挖掘量化分析背后隐藏的新发现。深入探讨人物关系的具体变化机制,增补情感张力的定性分析。
再次,反思数字人文技术方法的局限。数字人文技术在量化分析上具有优势,但可能弱化文本细腻的叙事与情感表达,未来可尝试将定量与定性相结合,避免技术分析的单一化倾向。
最后,从停用词的空间分布分析中寻找灵感。可借助停用词分析进一步挖掘人物的语义特征,例如台词中高频出现的环境、身份和隐喻。探讨人物在特定场景或空间分布中的关系变化,为叙事结构和空间意义分析提供新视角。