"Maze" and "Time Difference": A Text Mining Study of the Flow of Time in *Dream of the Red Chamber*
Date: 2025-12-19
作者:王嘉杰、马诚
选题背景
在数字人文研究中,利用统计学的方法对《红楼梦》一书的作者归属问题的讨论一直是领域内的热点话题。1980年首届国际《红楼梦》研讨会上,美国威斯康星大学陈炳藻教授的《从词汇上的统计论〈红楼梦〉的作者问题》一文开创了该领域研究的先河,他利用词频统计方法对红楼梦前80回和后40回的用字进行了测定, 并从数理统计学的观点出发, 推断出前80回与后40回的作者均为曹雪芹一人的结论。复旦大学数学系李贤平教授则选取47个虚词作为特征向量进行聚类分析得出前80回与后40回出自不同人之手的结论。以上两项研究都是利用数字人文的方法在红楼作者归属的研究,同时,数字人文领域内还有前人大量关于文本情感、人物关系、写作模式发现、可视化等方面丰富的研究成果。
但是纵观全部以文本挖掘技术为基础的数字人文研究,我们发现前人并未着重关注到小说文本中一个重要因素——时间。我们对小说文本中的时间定义有两种:一为“文本结构时间”,即小说根据章节、段落的顺序自然形成的,在读者阅读过程中感受到的真实自然时间的存在,例如《红楼梦》有120章回,那么这120章回就构成了《红楼梦》的文本结构时间;二为“小说情节时间”,即小说中故事发生的虚构时间,有可能在一章中小说情节时间过去了一整年,也有可能连续几十章都在描述其中一年的故事,这就导致了文本结构时间与小说情节时间之间的时差。时差的存在使得故事本身更加扑朔迷离,对时差的研究也可以帮助读者和研究者更好的理解小说内容。
数据引入
1.数据概况
我们分章节收集了简体版的《红楼梦》文本,以txt文本文档格式进行存储,以章节名称进行命名,总计在本地存储120个txt文档,利用R语言的循环函数对其进行数据读取。单个文档内容分布如下:
图1 文本文档概况
文档中对标题、段落之间的分隔使用了空行,同时存在大量缩进,这是在文本读取过程中需要格外注意并解决的文本读取问题。
2.文本读取
我们使用R语言进行文本读取,目的为将非结构化文本转化为结构化数据,标识文本结构时间。第一步是将目标文本读取到程序中,我们利用了原始文本中用于分格段落的空行,通过识别空行将同一txt文本中的段落进行识别。我们对每一个文本文档中的每一段落增加“chapter”和“seq”两个字段进行标识,“chapter”标识段落所属的章节,而“seq”表示段落在该章节中的次序。我们标识了三种段落类型:标题、正文和诗句,并删除了段落字数小于20的正文段落。
通过以上处理,我们将非结构文本初步转换为结构化的数据,并且使用章节和段落次序两个变量来标识文本结构时间。初步结构化数据集的五列分别代表:段落文本、段落字数、段落类型、段落所属章节和段落全文次序,具体结果如下:

图2 初步结构化数据
3.研究问题与分析流程
在获得可用于初步分析的的结构化数据后,我们对基于时间密度分析的核心问题进行了分阶段的拆分:第一阶段:时间标注,我们利用人工确定的时间线索词汇对所有文本进行内容匹配,以此在已确定的文本结构时间的基础上标识小说情节时间的线索词,以此关联文本结构时间和小说情节时间;第二阶段:人名标注,我们首先通过词频统计选出红楼梦小说情节中出场次序排名前20的角色,然后以相似的方法匹配出所有文本中出现的角色数,获取人物时间线,通过人物时间线的信息对时间流速问题进行进一步的说明;第三阶段:利用LDA主题聚类对全部文本内容分章节进行聚类,利用文本主题挖掘的方法从时间和角色两个维度进行聚类观察额外的时间信息。
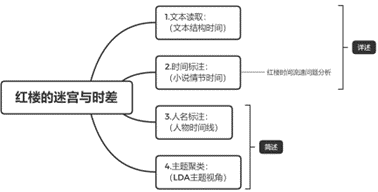
图3 分析框架
时间密度分析
1.时间标注
时间标注的核心目的为标识小说情节时间,推断时间流速。技术实现方面,本研究主要解决的两个问题为:一,识别出小说中所有的对话文本,对其进行删除;二,将已有的时间线索词汇与全文内容进行匹配并计数。对对话文本的删除的原因是因为对话中提到的时间词往往并不是由小说中故事发生的虚构时间确定的,可能是在对话中引述前年的事件而出现的词,这种词会对我们梳理真实的时间造成极大的干扰,因此讲其剔除。
我们构建了对话的正则表达式,利用它和自然语言处理方法对原始文本中的对话文本进行删除。以第1章第24段落为例,原始文本与剔除对话后的文本内容如下:

图4 对话剔除比较
同样,我们利用人工确定的时间线索词汇,包括季节、节气、月份、花和节日等可以确定具体时间的词汇,使用自然语言处理方法为每一章节的每一段落匹配这些词汇,使得在我们先前得到的一整条文本结构时间的基础上,去累加一条对应的小说情节时间,从而推断红楼的时间流速。
图5 时间线索词汇(部分)
值得注意的是,部分时间线索词汇在文本中还会出现在其他位置,例如“春”字也会出现在名字中,如“探春”、“惜春”,对于这种情况我们要做集合的减法以保证时间词的准确性。经过上述处理之后,我们得到了关联了小说情节时间的数据,结构如下:

图6 结构化数据集(关联小说情节时间)
2.时间密度分析
定义时间密度:D=Δt/Δn,其中Δt为小说情节时间间距,Δn为小说的章节间距。时间密度可以反映小说情节时间在每一章回的流速。时间密度越小,流速越慢,作者写作越详细,笔墨越多。
节气图分析:横轴方向,先去掉两头两尾,即15回以前和80回以后,因这些部分节气信息很少,很难获取有用的时间线索,计算出来的时间密度往往误差很大(数据越少,越不精确。比如第一回出现了元宵,到第十七回出现的元宵,显然间隔不止一年,第一回宝玉还没出世,而第十七回宝玉已经能够作诗了)。然后关注间距的最小值。找出两点对应的文本。任何比这个最小值大的节气通通不考虑,因为相邻两点不一定间隔一年,但一定大于等于一年,因为一年里不可能有两个相同节气。经过筛选,我们重点研究“元宵”、“春分”、“清明”三个节气。因为它们间距都差不多。两处的元宵节对应于第十七回和第五十四回,这两回说明都发生在小说某年的正月十五前后,同时注意到第二十回的时候,王熙凤在训斥赵姨娘的时候说到“大正月”,可见到了第二十回依旧还是正月,从这里可以发现,从第十七回到第二十回都在写正月,时间流速是比较慢的,所以我做出了大胆的假设:从第十七回到第五十四回(两个元宵节)只经过了一年。(也有可能是两年或以上,但是接下来就要去论证为什么是一年)这里我采用的思路是假设检验法,即先假定17—54是一年的时间,然后再去验证它对不对。之前提到了,去掉两头两尾以后我们的节气信息还是挺多的,而节气对应于一个时间,所以论证假设难度并不大。我们把这一年的时间定义为红楼n年,此时宝玉n岁(定义红楼元年宝玉1岁,红楼零年宝玉未出世),至于n的取值是多少先不去深究,先来证明刚才的问题。第一步,缩小研究范围。由于我们只证明17—54是同一年,因此把这区间外的信息全部抹掉,只看这个区间内的信息。现在我们开始从17开始,沿着横轴向右,观察纵轴中节气的变化。首先经过的节气是清明,对应于22,然后我们记为(22,4月5日),再接着就出现了矛盾:24回是端午,27回是芒种,29—31又是端午。这个时候千万不要认为自己的结论错了,而应该把出现端午的地方提取出来,看看当时的语境。果然,在调出文本以后,发现24回的端午是这样出现的:“凤姐正是要办端阳的节礼……”所以这是个将来时态。因此不矛盾,这下我们可以标记(27,6月5日),(31,6月14日)(暂且将端午换算成阳历)。再继续往下面看,45又出现了矛盾,春分和秋分同时出现了,然后再看看出现的地方,发现原文是这样的:“黛玉每岁至春分秋分之后,必犯嗽疾,今秋又遇贾母高兴……”因此,从语境里可以推出此时应该是秋分前后,而不是春分,所以依旧不矛盾。标记为(45,9月23日).接着往下看,就是53回的除夕和元宵了,这个单看回目就知道,而且元宵还花了两个回目写,所以记为(53,14月1日),(54,14月15日),至此,17—54的时间轴大致就可以画出来了(忽略阴历和阳历的换算误差)。我们可以得到7个点,分别是:(17,2月15日);(22,4月5日);(27,6月5日);(31,6月14日);(45,9月23日);(53,14月1日);(54,14月15日)。这样通过两点连成的线段的斜率就可以定量的反映时间密度的大小。斜率越大,时间流速越快,时间密度越大,说明作者是一笔带过的。而那些时间流速低的地方说明作者写得很详细,浓墨重彩。那么至此,是否就可以证明17—54是一年的时间呢?有人会这样问:万一清明是红楼n+1年的清明,芒种又是红楼n+2年的芒种……这种情况也是可能存在的呀,那么结论是不是就不成立了?其实提这个问题的人思考都很严谨,所以为了进一步论证假设,我们还需要一些佐证,从而使结论更有说服力。
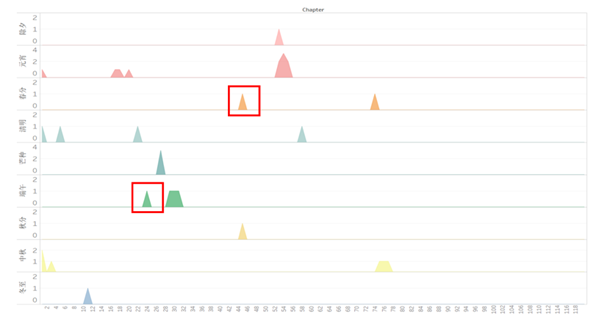
图7 节气分布图(原始数据)
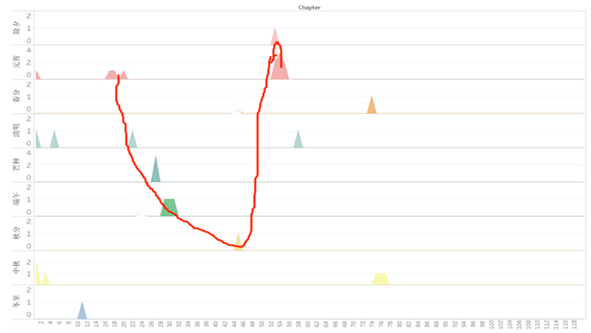
图8 节气分布图(时间曲线图)
月份图分析:现在我们来看另一张图,即月份图,月份是比节气更加直接的时间线索,而且数据量更丰富。如果我们的结论又能吻合月份图,那么就更加具有说服力了。还是一样,只关注17—54,首先我们就发现矛盾:第17回同时出现了十月和正月。和原文比对发现,这一回里面确实包含了十月的,也就是说这一回的十月是红楼n-1年的十月,因此不矛盾。于是我们记录(17,正月)。沿着横轴再往下看,就是三月,对应于24,记为(24,三月)。再接下来是四月,对应于(26,四月),然后五月的时候出现问题了,因为31出现了正月。原文比对发现,31的正月是回忆性文字,因此不属于情节实际时间。所以五月份也没有矛盾,记为(29,五月),之后的点一直是单调下降的,也没有出现一个回目里有多个月份共现的情况,因此符合假设。接下来的数据记录如下:(37,八月);(43,九月);(48,十月);(53,腊月)。需要特别指出的是,这里的月份都是阴历。现在,我们已经从节气和月份两个角度去验证我们的猜想了,或许有人还是不服气,说也有可能是n+1年的三月,n+2年的四月等等,但是,我们的结论已经通过了两个角度的论证了,都符合得很好,这就足以说明它的正确性。最关键的是,节气时间轴和月份时间轴的坐标也是惊人的一致。
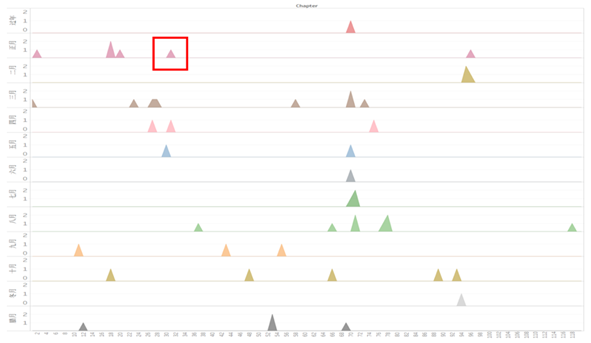
图9 月份分布图(原始数据)
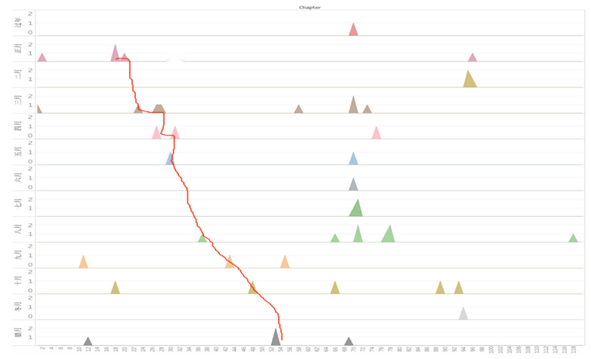
图10 月份分布图(时间曲线图)
现在我们可以肯定地说,17—54都在描写同一年发生的事,相当于全书近1/3的篇幅都在写一年。而我们知道,全书120回是宝玉的成长史,时间跨度为二十年,平均来算应该是六个回目描写一年,因此17—54,也就是红楼n年这年,时间流速是极其缓慢的,那么这一年到底有什么特殊性?作者为什么要对这一年浓墨重彩?

图11 红楼时间轴
为了探究这背后的原因,我们必须要先确定,这一年宝玉是多少岁,正处于什么样的人生阶段。这时需要进行文本细读了,注意到,在红楼梦第二十五回,空空道人对着玉念了咒语:“青埂峰一别,展眼已过十三载矣……”这里的十三载绝对不是随随便便写的,所以这个地方可以推断出宝玉此时是13岁,也就是说,第25回的宝玉是13岁,那么第17到54回的宝玉也就是13岁,n的取值就是13.那么说明1—16回的时间跨度是12年,平均每回目跨度0.75年,17—54回是每回目跨度0.026年,如果继续仿照前面的时间分析方法,画出55—80的时间轴来,可以发现这里的时间跨度是4年,因此平均每回跨度0.16年。80回以后我们会发现,时间线索非常少,因此要得出准确的时间轴是非常困难的,这里就不做探究了。通过对比发现,红楼13年的确是一个特殊的年份,不仅占了全书篇幅的1/3,而且全书的精华基本都在这一部分里,这一部分贾府达到了空前繁荣,从第17回元妃省亲到第54回元宵夜宴,以及中间部分的诗社的兴起,我们看不出这样的钟鸣鼎食之家会隐藏着危机,更不会联想到“树倒猢狲散”的场面。可是从第55回开始,小说的音律变了,人物之间的矛盾突然多了,中秋佳节也是“异兆悲音”,贾母大寿也是“嫌隙人有心生嫌隙”,到了抄检大观园以后,我们已经有一种“山雨欲来风满楼”的感觉了。所以17—54回是贾府最鼎盛的时期,作者当然要把所有的精华用在这一部分,因为这一年,或许也是作者最为难忘的一年。
下面我们来简单做个一一对应,假设小说中的人物有些是有原型的,我们最先想到的就是曹雪芹是不是就是宝玉的原型。这里我们姑且认为是。那么曹雪芹13岁那年到底发生了什么?目前官方的资料显示,曹雪芹的出生日期是1715年,13岁那年也就是1728年,这一年是雍正六年,根据文献记载,曹家在这一年被抄家,从此一蹶不振。曹雪芹是亲身经历过自己的家族由盛转衰的过程的,而且他也一定对抄家前的那一年记忆尤为深刻,因为那段时光太值得怀念了。所以在后来的红楼梦创作中,他格外对他13岁那一年充满感慨,因此在红楼13年这一部分,倾注了他大部分血泪。
3.人物时间线分析
在以上经过文本结构时间和小说情节时间的时间密度分析之后,我们对红楼120章回对应的时间密度问题已经做了较为详细的分析,接下来我们对以上分折的结果做不同维度的补充。首先,我们用类似的方法对红楼梦中出现的角色进行了文本内容的匹配。因为我们只需要对红楼中的主要角色进行分析,因此在具体描绘人物时间线之前,我们首先对所有角色在剔除对话后的文本中的出现频次进行统计,选出其中排名前二十的角色作为红楼的主要角色进行分析。
在获得新的人物出场次序时间线后,从数据中来看实际就获得了文本结构时间之上小说情节时间和人物时间线的对应关系,根据这一对应关系我们可以获得两者之间的相关性,根据皮尔森相关系数的计算方法,计算小说情节时间和人物时间线两条向量之间的相关性,按相关性从大到小进行排序,排序结果如下图所示,其中蓝色结果表示两者之间的相关性大于0,橙色结果表示两者之间的相关性小于0:
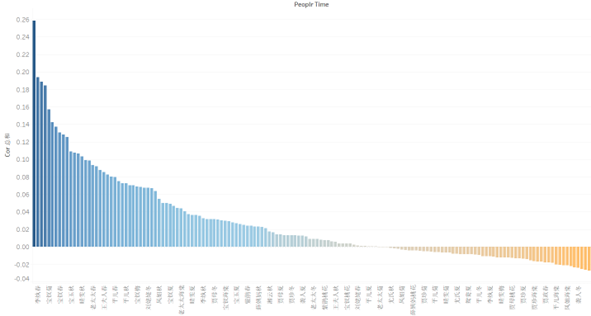
图12 小说情节时间与人物时间线的相关关系图
选取相关性最大和相关性最小的部分,展示其中的内容我们可以发现一些比较有趣的结论,比如与菊花的相关性比较高的有湘云、宝钗,说明他们的情节内容多发生在秋季,而与春天的相关性比较高的有李纨、尤氏、贾母和黛玉,说明他们的故事多发生在春季。不同的季节里不同角色的出场以及他们的故事、命运总有差异,根据这种相关性的计算可以看到在各个季节,与该季节相关最紧密的人物分别是谁,以此来构建人物与季节之间的一道关系。
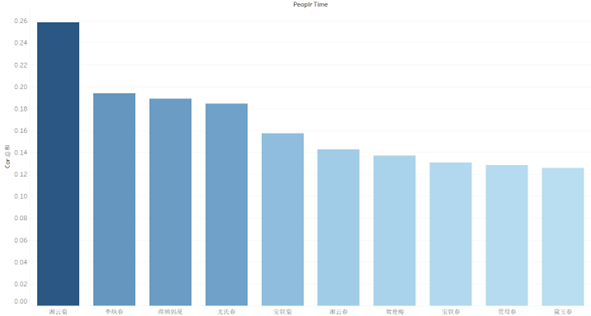
图13 正相关性
同样的,我们也可以看到不相关的排序,但是我们发现不相关的相关性最大也不到-0.03,这说明负相关性并不显著,所以不予以考虑。
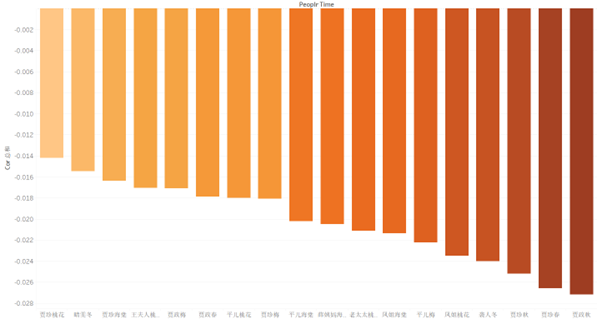
图14 负相关性
同样的,我们将人物时间线放置到文本结构时间的时间尺度上,可以看到人物出场次序随小说文本结构时间的递进而出现的高低变化,人物出场次序的变化究竟与小说情节时间有何关联,这是本研究暂时并未深入讨论的内容,可以在后续研究中做进一步的探索,本研究的主要贡献是提出了时间密度这一概念,在这一概念下的各方面深入探索待后续再做。
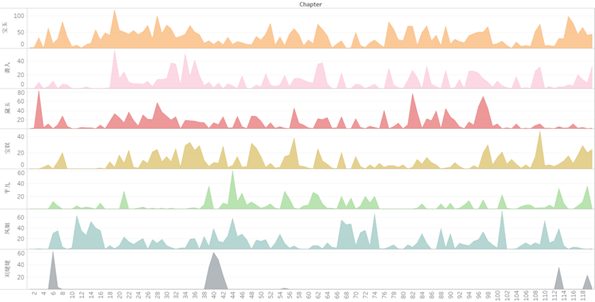
图15 人物时间线
4.LDA主题聚类
LDA聚类是经典的文本内容挖掘方法,传统的词频分析或者共词分析的方法也可达到揭示文本数据的研究主题的目的,但是关键词之间可能存在“共生现象”,可能有多个高频的关键词同属于一个主题,导致词频较低的关键词所属的主题难以发掘。并且传统的方法以关键词为研究对象,本身损失了很多语义信息,只能大致反映文章的方向,难以挖掘其隐含的语义信息,分析文本的规模也有限。而主题模型的出现,较好地解决了这一问题,不仅能够处理大规模的文本数据,还能挖掘出语料中潜在的语义信息,因此本研究尝试使用LDA主题聚类对《红楼梦》文本进行主题挖掘。
(Latent Dirichlet Allocation,LDA)潜在狄利克雷分配模型,是一种常见的主题模型,2003年由Blei等人共同提出。可以认为LDA是PLSA(Probabilistic Latent Semantic Analysis,概率潜在语义分析)的拓展,LDA使用了先验分布,克服了学习过程中的过拟合问题。该模型假设:1)主题由词的多项分布表示;2)文档由主题的多项分布表示;3)主题-词分布和文档-主题分布,两者的先验分布都是狄利克雷分布。借由狄利克雷分布是多项分布的共轭先验分布这一特性,可以通过观测的单词序列,推断出文档-主题分布和主题-词分布,挖掘出隐含的主题层,其生成过程见下图:
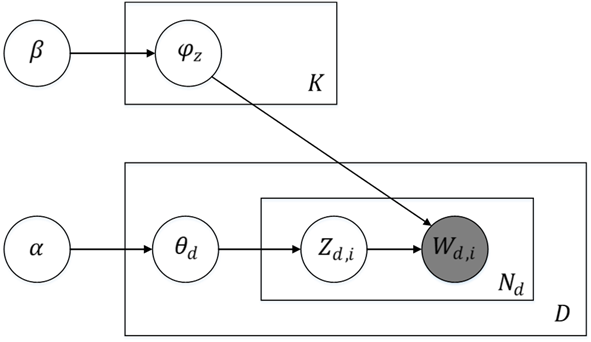
图16 LDA的板块表示
LDA模型将代表文本的词频向量(文档-词频矩阵)作为输入,通过迭代,输出推断出的文档-主题分布、主题-词分布,即每个文档由各个主题生成的概率、每个主题包含各个词的概率。图16中的节点表示随机变量:实心节点表示观测变量,空心节点表示隐变量;有向边表示概率依存的关系;矩形板块表示重复,板块内数字表示重复次数。图16中使用的符号及其含义见表1。

LDA主题模型的参数估计过程其实就是根据观测变量的取值估计隐变量的值,其参数估计的方法主要有三种,分别是:吉布斯采样算法(Gibbs Sampling)、变分推断算法(Variational Bayesian Inference)和期望最大算法(Expectation Maximization),张健伟[13]通过实验发现期望最大算法在某些关键的预测能力能力指标上(例如:预测混淆度)优于其他两种算法,并且可以在较短的时间内收敛,因此本研究采用期望最大算法来进行LDA主题模型的参数估计。
接下来看一下根据LDA主题建模框架,从时间和角色两个维度进行建模,时间维度建模我选取了所有由月份、季节、花、节气构成的小说情节时间,角色维度建模我选取了所有人物时间线,建模获得以下模型结果。图17、19是两个维度下的主题,我们发现当设置主题数为4时,时间维度刚好形成完美的春夏秋冬四个主题,而当设置主题数为6时,角色维度则刚好形成数对有趣的角色搭配,包括“宝玉-袭人”、“贾母-贾珍-尤氏”、“凤姐-平儿”和“宝玉-黛玉”等,说明《红楼梦》小说中存在明显时间和人物主题。
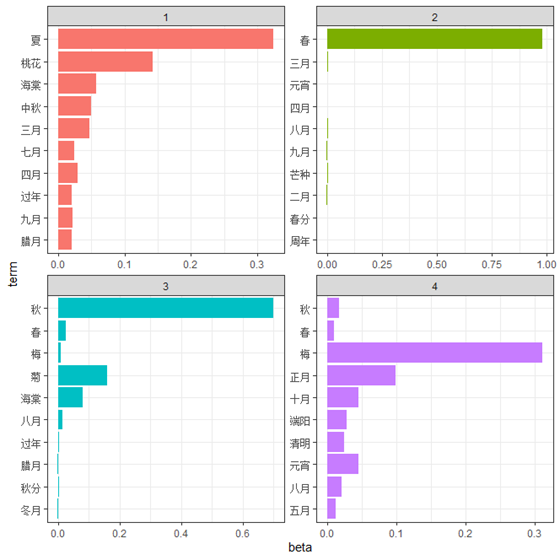
图17 时间主题
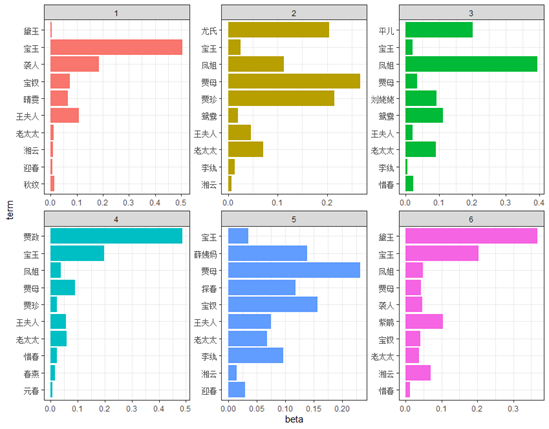
图18 角色主题
接着将每一章节用时间和角色两个维度的主题进行描述,最终呈现在文本结构时间上,展示如下两图所示。每张图可以展示不同主题随文本结构时间的递进而产生的量上的变化,由于目前尚未对该曲线进行平滑,直接从图中很难得到有用的信息。目前本研究先是获悉了使用LDA主题聚类方法进行数字人文研究的可行性,进一步的探索留到后续研究中进行。
图19 时间主题时序展示
图20 角色主题时序展示
总结
本次研究到此就算全部结束,我们整理所有的构想、模型拟合和算法实践,列出以下四条提纲挈领式的经验总结:
1. 在利用数字技术处理文本信息时,最先也是最重要的问题就是第一步:数据读取,因为文本数据总是非结构化的,但是我们在做处理时需要数据是结构化的。因此如何将非结构文本转化为结构化数据是需要认真考虑的。在我们的项目里,初期我们计划文本结构时间的最细粒度是每一章节,但是在处理数据时,发现技术手段可以帮助我们定位到段落,因此我们将文本结构时间精确到了每一章节的每一段落。
2.在数据处理过程中要确认:
数据的真实含义是什么?例如我们定位元宵这个词,我们的本意是识别小说文本中的时间。但是如果我们没有意识到元宵这个词有小说描述性文本和对话文本的差异,那么识别后的结果将被引入大量误差。在数据分析的过程中,误差是非常可怕的。trash in, trash out。
在自然语言处理和数据分析的过程中,信息保留程度是需要权衡的,保留信息越多那么可能获得的结果越多,但是随之引入的误差就越大,对数据处理的要求越高。
3.在对结果进行人文阐释时,要善于利用数字技术的优势进行阐释,而避免走入“使用数字技术处理后却依然从传统文学研究的视角去看待结果”。例如本研究中我们引入了时间密度这一概念,虽然说这一概念完全可以通过传统文学研究,利用人工的方式手动标注时间线来确定红楼梦本身的时间流速。但是本研究提出的方法是具有普适性、可迁移的,是可以继续用于其他不同小说作品,甚至文学体裁,散文、诗歌、音乐等等中去,这是本研究作为数字人文研究的一大关键核心点,也是相较于传统研究的优势。