Chinese Commercial Advertisement Archive
Date: 2018-03-06 Chen Jing
简介
什么是中国商业广告数据库(CCAA)?
CCAA是一个面向图像的研究型在线档案馆。它由超过18700多张拥有44个元数据的高画质数字广告图像组成。所有的广告图像数字化于中国最重要的五个通商口岸城市的商业报纸的高质量微缩胶卷,而这五个城市及其对应的报纸分别是上海《申报》、天津《大公报》、沈阳《盛京时报》、汉口《汉口中西报》、广州《越华报》。这些档案资料分别收藏于中国国家图书馆、上海图书馆、广东省孙中山图书馆、清华大学图书馆和华盛顿大学西雅图分校的亚洲语言图书馆。在一项由鲁斯基金会资助的“视觉蜉蝣”项目下,在莱斯大学教务长办公室,人文学院院长办公室,赵氏亚洲研究中心的支持下,项目负责人白露教授,陈静博士也是鲁斯博士后与一群历史学家、图书馆管理员、程序设计员、硕士及本科生一起在2010年启动了该项目。你现在可以通过浏览网站查看和利用该项目的成果。
CCAA的目的
在最简单地层面上,我们想回答的问题类似于:在1928年,上海消费者可以买到多少种外国品牌的商品?答案是:雪佛蘭, 福特和達極的汽车;法本公司和英国卜内门公司的化学肥料;仁丹,補而多和兜安氏的保健品;珂路搿(高露洁)牙膏,旁氏冷霜,棕欖香皂;三得利威士忌,朝日啤酒,桂格麦片,阳光少女葡萄干,凡士林,everyday手电筒和电池,固特异轮胎,纽约美孚石油公司的石油和天然气产品,英美煙品牌,利华兄弟公司的产品比如利华洗衣皂,以及通用电气公司产品,从城市路灯发电机到家用风扇。而这些只是我们收集的信息中微不足道的一小部分。这五个城市的广告充斥着各种各样的商品,而每一个做广告的公司都挣到了钱。
但我们也可以问一些更深层次的问题,比如说:从这一时期的中国商品广告中我们可以学到什么?我们可以轻而易举地看到这个档案中的很多广告描述了性别的规范和愿景。比如说有一种日本药片可以帮助中国男性更强壮,而有很多商品的广告图片对由一对父母和两个孩子组成的现代小家庭进行了理想化描绘。许多广告的内容是表现现代女性形象运用复杂科技(比如使用柯达的相机拍照、驾驶福特的汽车和聆听百代唱片),而这些使他们成为了现代女性。将CCAA的收藏与其他数据来源结合在一起,我们就能对阶级分层与都市消费社会的了解更多。比如,有一项关于英美烟草公司的著名研究就显示了BAT公司是如何深入到农户家用搜集信息的,使得代理商可以定一个比较低的价格但是还可以获得利润。当我们将我们的材料与这些研究关联起来,我们就能理解阶级分层、商品市场和销售策略。
但是,数字化和数据挖掘会使我们不得不去问一些之前未曾考虑到的问题并且这些问题在成千上万的广告文本和卡通画中并不会显而易见。举例来说,因为这些品牌都来自国外时,他们的广告是如何迎合现代中国“特色”的呢?考虑到许多外国品牌用中国名人来推荐它们的产品,那这些品牌会与民族主义相符还是相悖?或者说回避了民族主义问题?在中国的发达城市里制造新的商品文化过程中,所谓的中国价值是否已经发生了变化?当人们在买一个品牌商品而不是一个普通商品时,从概念上来说,人们不得不放弃了什么?用马克思语言来说,就是这些疑问使我们面临使用价值和交换价值的问题,而这些问题正是社会商品化和社会分析的关键。从统计上来说,我们可以提问并解答深藏于广告中最重要的概念是什么以及它们之间的相对重要性。如果我们能够研发语境发现系统,我们就可以期待在该系统搜索之后得到一个文献,为学者尽可能多地提供语境信息和环境,从而可以观察、探索、分析、关注以及拓展语境去进行解释。
数字人文为提问提供了独特的方法。我们尝试使用深度学习的方法去量化广告绘画,或者说“卡通”。因为已经有了绘画分析的技术,我们就能利用这个技术去了解这些在早于广告的绘画中绘制了这些素描和当代陈词滥调的艺术家们。这些广告和素描艺术反映了城市中的社会日常和普通人的生活,但不倾向于售卖商品。广告是最重要的一种商业艺术,但这还不是全部。数字档案库允许我们做文本挖掘。文本挖掘提供了方法量化书写语言并揭示了书写使用的语言样式。尤其是在早期广告中,书写文本扮演了重要的角色。收集这些文字意味着我们最终能“挖掘”数据,并将广告修辞与其它类型的文本进行比较,比较对象既包括现代中国文学、现代诗、中文的现代理论也可以是在此描述的过程中产生的问题。换句话说,数字人文使得中国城市中包括广告或商业艺术在内的新印刷媒介的形式、技术、混合媒介以及艺术传统得以可能。算法也指导我们将新广告语言隔离起来并语境化。CCAA收集中文的那个阶段较之之前发生了巨变。全世界所有的本地语言都创造新的词和语法鼓励人们购买商品而中国并例外。数字人文基础设施开启了思考语言和语言变化的新方式。
最后,我们可以让这些数据告诉我们关于一种被文化历史学家称为“渴望”的抽象力量。通常当历史学家推测人类动机时,我们除了自己的决心外,基本没有什么证据也没有东西能够指导我们。但是我们知道过去的人们殷切渴望着不同的品质和物品。为什么人们会买一瓶比葡萄籽油贵十倍以上而功能一样的凡士林牌罐装甘油呢?时尚是商品文化的关键,核心是一次性消费以及购买拥有短暂生命的东西的意愿和能力。数字资料使我们可以具体描述一些学者称为有关商品的“情感结构”和“欲望制度”的东西,我们还知道,这些商品正是当时的人每天能看在广告上看到,并且购买的。广告与广告数据的数字化和统计处理帮助所有的殖民现代历史学家解决了一个基本问题,即为什么现代人会买寿命相当短暂的商品然后将它们扔掉?
是如何实现这些的?
首先我们创建元数据,这意味着在收集我们的历史资料之后,我们将其描述并将其分类为自然或内在于图像的信息类别。例如,我们有人、车、房子、城市空间、动物等的分类。其中比较重要的就是性或者性别。现代广告立刻关注到了使用可爱的女性形象去推销商品。不是每个商品广告都将使用价值与妇女形象联系在一起,但它们即使没有一个女孩的图像,也会使用男性和女性情侣、父母和小孩、以及核心或者现代家庭的图像。这些信息汇总成为了我们成为性别的元数据。元数据可以描绘小以及大数量的证据,因为在这个过程中,材料的数量并不是关键。然而我们已经收集了大量的材料(最终有了五份报纸的广告,描绘的案例跨越一个多世纪)。这些图像自身是复杂的,我们又对其几十年的历史进行了持续研究,因此我们的研究过程也变得复杂。
将大量证据分解为元数据后,我们得到了一个“数据集”。数据集使得内容分析具有了可能性,这就意味着数据的算法计算得以可能,反过来也意味着我们得以问数据更多此类的问题。比如,核心城市是否在城市中交易商品,还是它们以都市核心周边的农村为目标?因为广告不仅仅是一种实践,而且是一套社会科学观点,所以广告中的语言在5、60年间发挥了什么样的角色?考虑到与中国当时正在发生的语言革命有一定关联,那广告的语言是如何变化的?这对历史学家和其他人文科学研究者而言,都是至关重要的。数字档案不仅仅允许我们去考察的,不仅仅是一个品牌,而是一个公司拥有的多个品牌,比如通用电气或者英美烟草公司,亦或是福特公司。更重要的是,我们可以揭示广告市场潜在的本地差异。我们已经能够看到,在上海,天津和沈阳的广告市场上,当地方性广告呈现出性别化的人物形象时,也用了不同的语法和不同的风格。我们确实不知道市场、市场制造者、广告代理商是否对地方的偏好敏感?又是如何敏感的?没有数字档案库,我们是没有方法去估计或测量这种差异。将信息分散到元数据中帮助我们测量地方主义。甚至一百年以前, 中国的都市或者说“贸易口岸”篇幅辽阔,有着非常复杂的地方历史系统。CCAA的贡献之一就是可以将图像数字化为数据,并发展文本挖掘使得我们得以推动内部的比较。
元数据是如何工作的?
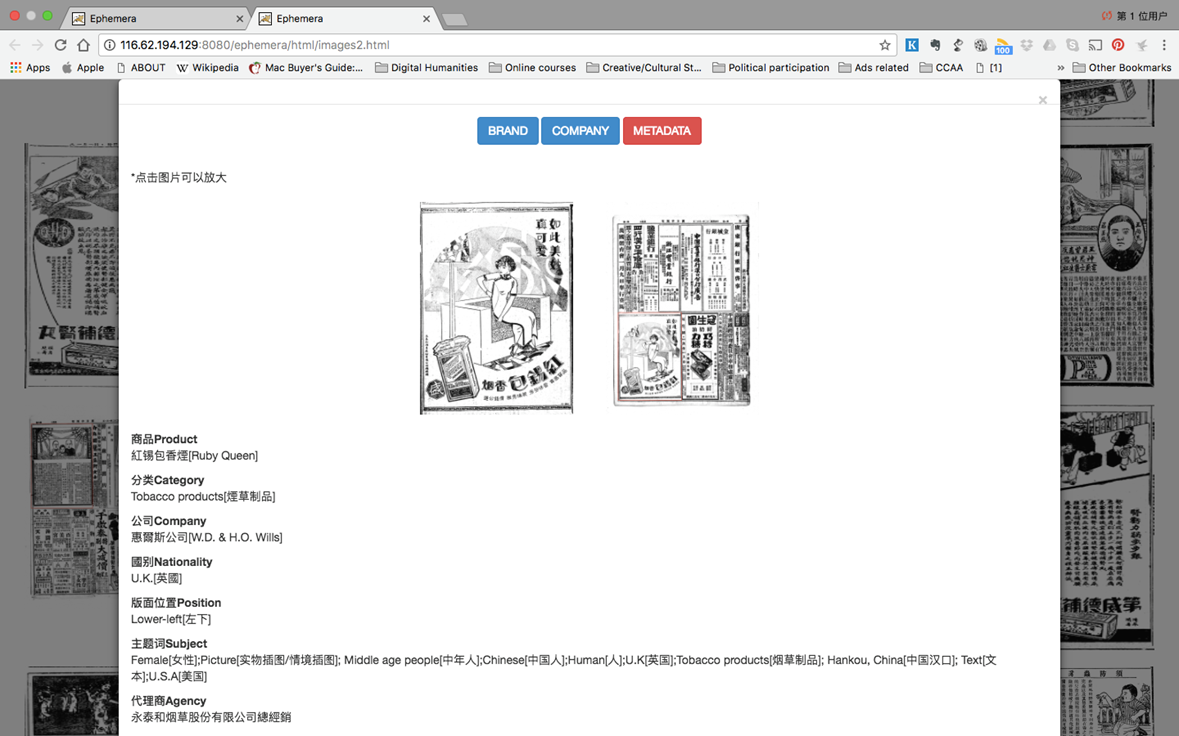
元数据是CCAA的核心。作为以研究主导,以图像为对象聚焦的在线档案馆,CCAA致力于记录所有相关信息,如广告插图或场景,品牌图标,语言和词汇,以及地图信息,如街道名称和公司名称。经过漫长的学习和测试过程,我们得以开始将基于都柏林数据标准定制的元数据标准应用于每一个广告的每一张数字图片中,我们持续的建立元数据的权威性、兼容性、一般性和持续性。这些元数据包括关于图像内容的描述性数据、与图像有关的商品和广告业的语境信息数据、报纸的文献数据以及关于数字文件的技术数据,比如图像的来源、报纸出版社所在地、版权状态和所属机构。
描述性元数据主要描述了每张广告图像的文本和图像元素。广告包括以下要素中的部分或者全部:全文、广告标题、广告语、人物形象或者动物、人物形象中的男性或者女性等。用元数据术语说就是标题、关键词、全文转录的文本以及对整个图像的一般描述。我们定制的一些要素将帮助那些需要一些基本数据/信息的研究者在他们点击和下载某个特定图像之前,能够快速地整个数据库进行搜索。在未来的研究中,我们将进一步对广告图像中的视觉图表和全文进行深入,将之转换为可以进行文本挖掘的数据,从而可能应用于新的、更为高级的分析方法。
第二类元数据主要是生产和传播图像的商品和广告业的语境信息。我们认为广告图像是图像设计也是文化产品,是经济商品也是社会商品。正如下图所示,我们用了包括品牌/名称、商品类别、公司、代理机构、公司地址和代理机构地址等在内的元数据。其中一些是我们直接从图像的内容中提取的; 一些是我们从外部资源获取加入到元数据中的。比如,我们知道如何在每个广告中找到商品的品牌或名称,但是并不是总能找到找到制造公司、发行机构或制作广告并将其投放报纸的广告代理商的信息。
我们使用代码表来解决这个问题,并确保数据是一致的。但经验告诉我们,代码本身还需要时时被更新和关注,因为在某些特定的报纸里,几十年间信息会因为新的拥有者及本地市场的变化而变化。
我们使用一组关键字来描述图像,例如:1)动物、植物、人形象的图像类别,包括女性/男性,老年/青年/中年人,外国人/中国人,儿童/婴儿等子类别; 2)设计风格,包括包装插图,情境插图和文本; 3)文本信息,指的是生产公司的国籍和地点。这些关键词统称为“主题”。网站还支持相应的搜索功能,并为CCAA用户提供了一个简单的访问全部信息的链接。
第三类元数据提供了关于广告的核心环境信息。比如CCAA文献数据总结了所有关于广告所在的报纸的出版信息,包括“期号”、“刊号”、“位置”、“页码”、“报纸出版商”、“发行日期”、“印刷厂”和“编辑”。这些数据将为研究人员提供背景信息并帮助他们找到原始报纸,并得以展开关于一年或多年内在一家或几家报纸上发布的特定广告的频率信息的统计分析。
技术数据描述了数字化和归档的技术过程。其中ID是每一张广告的图像文件和数据文件的唯一身份号,可以确保图像和元数据条目的对应性。而“版权”是指该图像的版权所属及使用规定。CCAA采用了知识共享协议,允许用户在任何媒介以任何形式复制、传播数据库中的图片,但必须署名并不得用于商业目的或者进行再创作。同时该部分数据还说明了数字化过程中的相关参数及数字图像格式。
在哪里?
在两个网站可以使用CCAA:由莱斯大学的Fondren图书馆保存和维护的存档站点(scholarship.rice.edu)以及南京大学保存的蜉蝣项目的官方网站(ccaa.nju.edu.cn)。项目图像包括TIFF格式的底图(不可公开访问)和可下载的JPEG2000格式的图片(可公开访问). Scholarship.rice.edu是基于DSpace的机构资料库。项目图像及其元数据都存储并保藏在此平台上。然而,作为大学档案馆,Scholarship.rice.edu维护着数百个数据库,因此很难符合CCAA的定制化要求。
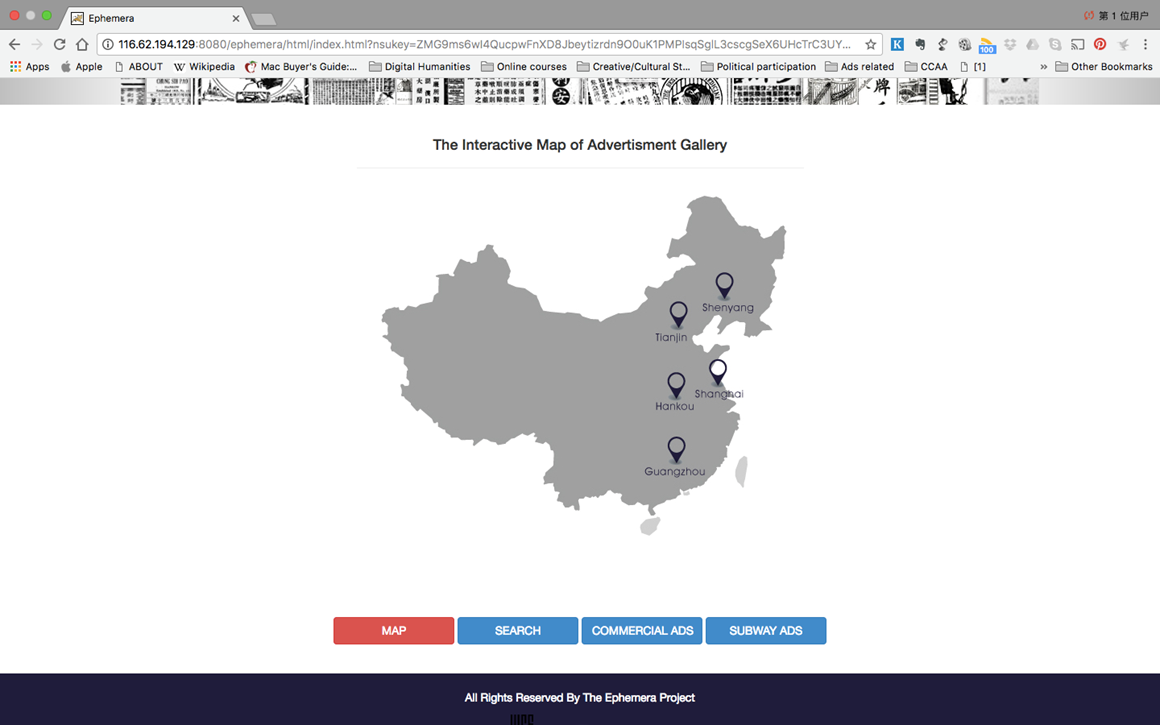
第二个CCAA的NJU网站以视觉为导向,拥有高价值的图形图像,为开展社会历史,文化研究,知识史,社会学和统计学相关的研究和写作提供了友好的机会接触到很大程度上被忽略了的资源。 CCAA网站不仅是具有可搜索资源的网站,它还吸引了全世界好奇的研究人员。每个单独的报纸都是CCAA系统中的一个集合。我们将持续建设网站,使得用户可以创建图像库、交互式地图、广告时间轴、交叉引用的动态链接、可视化统计分析,每周更新的新闻等。这是我们希望在接下来的几年内扩大和发展的项目的一部分。现在,我们的目标就是使得图片可被触及和搜索!我们希望你可以充分利用这个资源,也请在你的出版物种引用该数据。同时,如果你希望补充这个收藏或者希望你的出版物被网站引用,请联系我们!我们非常希望我们能一起建立共享的数据资源,为蜉蝣资源研究添砖加瓦。在我们的商业广告档案中向我们的用户发布并告知用户相关学术工作是另外一种推动并提升19世纪晚期20世纪初期中国日常生活学术研究的方式。
以下为网站部分截图

相关文献: